 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
假设根结点的层数为1,并设具有n(n≥3)个结点的二叉树的最大高度为h,设达到最大高度h时,不同的二叉
假设根结点的层数为1,并设具有n(n≥3)个结点的二叉树的最大高度为h,设达到最大高度h时,不同的二叉树的数目为m。有以下说法: ①h≤n ②h=[log2n]+1 ③m=1 ④m=2 ⑤m=2n-1其中正确的个数有______个。
A.1
B.2
C.3
D.4
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
假设根结点的层数为1,并设具有n(n≥3)个结点的二叉树的最大高度为h,设达到最大高度h时,不同的二叉树的数目为m。有以下说法: ①h≤n ②h=[log2n]+1 ③m=1 ④m=2 ⑤m=2n-1其中正确的个数有______个。
A.1
B.2
C.3
D.4
如果结果不匹配,请 联系老师 获取答案
 更多“假设根结点的层数为1,并设具有n(n≥3)个结点的二叉树的最…”相关的问题
更多“假设根结点的层数为1,并设具有n(n≥3)个结点的二叉树的最…”相关的问题
试题四(共15分)
阅读下列说明和c代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
设某一机器由n个部件组成,每一个部件都可以从m个不同的供应商处购得。供应商j供应的部件i具有重量Wij和价格Cij。设计一个算法,求解总价格不超过上限cc的最小重量的机器组成。
采用回溯法来求解该问题:
首先定义解空间。解空间由长度为n的向量组成,其中每个分量取值来自集合{l,2,…,m},将解空间用树形结构表示。
接着从根结点开始,以深度优先的方式搜索整个解空间。从根结点开始,根结点成为活结点,同时也成为当前的扩展结点。向纵深方向考虑第一个部件从第一个供应商处购买,得到一个新结点。判断当前的机器价格(C11)是否超过上限(cc),重量(W11)是否比当前已知的解(最小重量)大,若是,应回溯至最近的一个活结点;若否,则该新结点成为活结点,同时也成为当前的扩展结点,根结点不再是扩展结点。继续向纵深方向考虑第二个部件从第一个供应商处购买,得到一个新结点。同样判断当前的机器价格(C11+C21)是否超过上限(cc),重量(W11+W21)是否比当前已知的解(最小重量)大。若是,应回溯至最近的一个活结点;若否,则该新结点成为活结点,同时也成为当前的扩展结点,原来的结点不再是扩展结点。以这种方式递归地在解空间中搜索,直到找到所要求的解或者解空间中已无活结点为止。
【C代码】
下面是该算法的C语言实现。
(1)变量说明
n:机器的部件数
m:供应商数
cc:价格上限
w[][]:二维数组,w[i][j]表示第j个供应商供应的第i个部件的重量
c[][]:二维数组,c[i][j]表示第j个供应商供应的第i个部件的价格
best1W:满足价格上限约束条件的最小机器重量
bestC:最小重量机器的价格
bestX[].最优解,一维数组,bestX[i]表示第i个部件来自哪个供应商
cw:搜索过程中机器的重量
cp:搜索过程中机器的价格
x[]:搜索过程中产生的解,x[i]表示第i个部件来自哪个供应商
i:当前考虑的部件,从0到n-l
j:循环变量
(2)函数backtrack
Int n=3;
Int m=3;
int cc=4:
int w[3][3]={{1,2,3},{3,2,1},{2,2,2}};
int c[3][3]={{1,2,3},{3,2,1},{2,2,2}};
int bestW=8;
int bestC=0;
int bestX[3]={0,0,0};
int cw=0;
int cp=0;
int x[3]={0,0,0};
int backtrack(int i){
int j=0;
int found=0;
if(i>n-1){/*得到问题解*/
bestW= cw;
bestC= cp;
for(j=0;j<n;j++){
(1)____;
}
return 1;
}
if(cp<=cc){/*有解*/
found=1;
}
for(j=0; (2)____;j++){
/*第i个部件从第j个供应商购买*/
(3) ;
cw=cw+w[i][j];
cp=cp+c[i][i][j];
if(cp<=cc && (4) {/*深度搜索,扩展当前结点*/
if(backtrack(i+1)){found=1;}
}
/*回溯*/
cw= cw -w[i][j];
(5) ;
}
return found;
}
从下列的2道试题(试题五和试题六)中任选1道解答。
如果解答的试题数超过1道,则题号小的1道解答有效。
设单链表中结点的结构为:
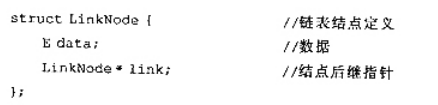
在一个具有n个结点的单链表中插人一个新结点,并可以不保持原有顺序的算法的时间复杂度是().
A、O(1)
B、O(n)
C、O(n2)
D、O(nlog2n)
A、n1-1
B、n1+n2+n3
C、n2+n3+n4
D、n1
●试题二
阅读下列函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
函数print(BinTreeNode*t;DateType &x)的功能是在二叉树中查找值为x的结点,并打印该结点所有祖先结点。在此算法中,假设值为x的结点不多于一个。此算法采用后序的非递归遍历形式。因为退栈时需要区分右子树。函数中使用栈ST保存结点指针ptr以及标志tag,Top是栈顶指针。
【函数】
void print(BinTreeNode*t;DateType &x){
stack ST;int i,top;top=0;∥置空栈
while(t!=NULL &&t->data!=x‖top!=0)
{while(t!=NULL && t->data!=x)
{
∥寻找值为x的结点
(1) ;
ST[top].ptr=t;
ST[top].tag=0;
(2) ;
}
if(t!=Null && t->data==x){∥找到值为x的结点
for(i=1; (3) ;i++)
printf("%d",ST[top].ptr->data);}
else{
while((4) )
top--;
if(top>0)
{
ST[top].tag=1;
(5) ;
}
}
}
阅读以下说明和C语言函数,将应填入(n)处的字句写在答题纸的对应栏内。
[说明]
求树的宽度,所谓宽度是指在二叉树的各层上,具有结点数最多的那一层的结点总数。本算法是按层次遍历二叉树,采用一个队列q,让根结点入队列,若有左右子树,则左右子树根结点入队列,如此反复,直到队列为空。
[函数]
int Width (BinTree *T
{
int front=-1, rear=-1; /*队列初始化*/
int flag=0, count=0, p; /*p用于指向树中层的最右边的结点, flag 记录层中结点数的最大值*/
if (T!=Null)
{
rear++;
(1);
flag=1;
p=rear;
}
while ((2))
{
front++;
T=q [front]];
if (T->lchild!=Null )
{
roar+-+;
(3);
count++;
}
if (T->rchild!=Null )
{
rear++; q[rear]=T->rchild;
(4);
}
if (front==p ) // 当前层已遍历完毕
{
if((5))
flag=count;
count=0;
p=rear, //p 指向下一层最右边的结点
}
}
return (flag );
}
阅读以下预备知识、函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【预备知识】
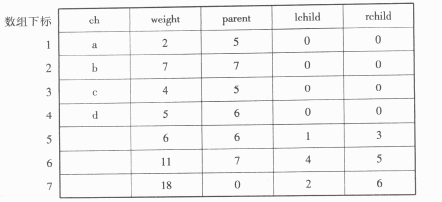
①对给定的字符集合及相应的权值,采用哈夫曼算法构造最优二叉树,并用结构数组存储最优二叉树。例如,给定字符集合{a,b,c,d}及其权值2、7、4、5,可构造如图3所示的最优二叉树和相应的结构数组Ht(数组元素Ht[0]不用)(见表5)。
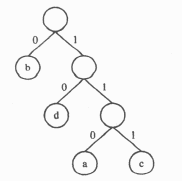
图3最优二叉树
表5 结构数组Ht
结构数组Ht的类型定义如下:
define MAXLEAFNUM 20
struct node{
char ch;/*当前结点表示的字符,对于非叶子结点,此域不用*/
int weight;/*当前结点的权值*/
int parent;/*当前结点的父结点的下标,为0时表示无父结点*/
int lchild,rchild;
/*当前结点的左、右孩子结点的下标,为0时表示无对应的孩子结点*/
}Ht[2*MAXLEAFNUM];
②用′0′或′1′标识最优二叉树中分支的规则是:从一个结点进入其左(右)孩子结点,就用′0′(′1′)标识该分支(示例如图3所示)。
③若用上述规则标识最优二叉树的每条分支后,从根结点开始到叶子结点为止,按经过分支的次序,将相应标识依次排列,可得到由′0′、′1′组成的一个序列,称此序列为该叶子结点的前缀编码。例如图3所示的叶子结点a、b、c、d的前缀编码分别是110、0、111、10。
【函数5.1说明】
函数void LeafCode(int root,int n)的功能是:采用非递归方法,遍历最优二叉树的全部叶子结点,为所有的叶子结点构造前缀编码。其中形参root为最优二叉树的根结点下标;形参n为叶子结点个数。
在构造过程中 ,将Ht[p].weight域用作被遍历结点的遍历状态标志。
【函数5.1】
char**Hc;
void LeafCode(int root,int n)
{/*为最优二叉树中的n个叶子结点构造前缀编码,root是树的根结点下标*/
int i,p=root,cdlen=0;char code[20];
Hc=(char**)malloc((n+1)*sizeof(char*));/*申请字符指针数组*/
for(i=1;i<=p;++i)
Ht[i].weight=0;/*遍历最优二叉树时用作被遍历结点的状态标志*/
while(p){/*以非递归方法遍历最优二叉树,求树中每个叶子结点的编码*/
if(Ht[p].weight==0){/*向左*/
Ht[p].weight=1;
if (Ht[p].lchild !=0) { p=Ht[p].lchild; code[cdlen++]=′0′;}
else if (Ht[p].rchild==0) {/*若是叶子结 点,则保存其前缀编码*/
Hc[p]=(char*)malloc((cdlen+1)*sizeof(char));
(1) ;strcpy(He[p],code);
}
}
else if (Ht[p].weight==1){/*向右*/
Ht[p].weight=2;
if(Ht[p].rchild !=0){p=Ht[p].rchild;code[cdlen++]=′1′;}
}
else{/*Ht[p].weight==2,回退*/
Ht[p].weight=0;
p= (2) ; (3) ;/*退回父结点*/
}
}/*while结束*/
}
【函数5.2说明】
函数void Decode(char*buff,int root)的功能是:将前缀编码序列翻译成叶子结点的字符序列并输出。其中形参root为最优二叉树的根结点下标;形参buff指向前缀编码序列。
【函数5.2】
void Decode(char*buff,int root)
{ int pre=root,p;
while(*buff!=′\0′){
p=root;
while(p!=0){/*存在下标为p的结点*/
pre=p;
if((4) )p=Ht[p].lchild;/*进入左子树*/
else p=Ht[p].rchild;/*进入右子树*/
buff++;/*指向前缀编码序列的下一个字符*/
}
(5) ;
printf(″%c″,Ht[pre].ch);
}
}
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。
[说明]
二叉树的二叉链表存储结构描述如下:
lypedef struct BiTNode
{ datatype data;
street BiTNode *lchiht, *rchild; /*左右孩子指针*/ } BiTNode, *BiTree;
下列函数基于上述存储结构,实现了二叉树的几项基本操作:
(1) BiTree Creale(elemtype x, BiTree lbt, BiTree rbt):建立并返回生成一棵以x为根结点的数据域值,以lbt和rbt为左右子树的二叉树;
(2) BiTree InsertL(BiTree bt, elemtype x, BiTree parent):在二叉树bt中结点parent的左子树插入结点数据元素x;
(3) BiTree DeleteL(BiTree bt, BiTree parent):在二叉树bt中删除结点parent的左子树,删除成功时返回根结点指针,否则返回空指针;
(4) frceAll(BiTree p):释放二叉树全体结点空间。
[函数]
BiTree Create(elemtype x, BiTree lbt, BiTree rbt) { BiTree p;
if ((p = (BiTNode *)malloc(sizeof(BiTNode)))= =NULL) return NULL;
p->data=x;
p->lchild=lbt;
p->rchild=rbt;
(1);
}
BiTree InsertL(BiTree bt, elemtype x,BiTree parent)
{ BiTree p;
if (parent= =NULL) return NULL;
if ((p=(BiTNode *)malloc(sizeof(BiTNode)))= =NULL) return NULL;
p->data=x;
p->lchild= (2);
p->rchild= (2);
if(parent->lchild= =NULL) (3);
else{
p->lchild=(4);
parent->lchild=p;
}
return bt;
}
BiTree DeleteL(BiTree bt, BiTree parent)
{ BiTree p;
if (parent= =NULL||parent->lchild= =NULL) return NULL;
p= parent->lchild;
parent->lchild=NULL;
freeAll((5));
return bt;

















