 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
信度系数不仅可以解释测验总变异中的随机测量误差,还可以解释:()。
A.样本标准差
B.组间误差
C.真分数变异
D.组内误差
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.样本标准差
B.组间误差
C.真分数变异
D.组内误差
如果结果不匹配,请 联系老师 获取答案
 更多“信度系数不仅可以解释测验总变异中的随机测量误差,还可以解释:…”相关的问题
更多“信度系数不仅可以解释测验总变异中的随机测量误差,还可以解释:…”相关的问题
如下简单的模型是来度量选校方案对标准化测验成绩的影响的[有兴趣的话,参见Rouse(1998):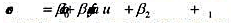 。其中,score是一次全州范围内的测验成绩;choice是一个二值变量,表示一个学生去年是否去所选择的学校上学;faminc是家庭收入。choice的Ⅳ是grant,即资助学生用于选校学费的美元数量。资助金额因家庭收入水平的不同而不同,因此我们在方程中要控制faminc。
。其中,score是一次全州范围内的测验成绩;choice是一个二值变量,表示一个学生去年是否去所选择的学校上学;faminc是家庭收入。choice的Ⅳ是grant,即资助学生用于选校学费的美元数量。资助金额因家庭收入水平的不同而不同,因此我们在方程中要控制faminc。
(i)尽管方程中有faminc,为什么choice还可能与u1相关?
(ii)如果在每个收入等级中,资助金额是随机分配的,那么grant是否与u1不相关?
(iii)写出choice的约简型方程。我们需要什么而使grant与choice偏相关?
(iv)写出score的约简型方程。解释它为什么有用?(提示:你如何解释grant的系数?)

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差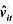 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用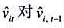 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为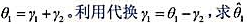 的标准误。
的标准误。
利用APPLE.RAW中的数据。这些电话调查数据是为了得到(假想的)“环保”苹果需求。调查者向每个家庭都(随机地)介绍了正常苹果和环保苹果的一组价格,并询问他们愿意购买每种苹果的磅数。
(i)对于样本中的660个家庭,有多少家庭报告称在预定价格上不愿意购买环保苹果?
(ii)变量ecolbs看上去在严格正值上具有连续分布吗?你的回答对ecolbs托宾模型的适当性有何含义?
(iii)以ecoprc、regprc、famic和hhsize作为解释变量,估计一个托宾模型。哪些变量在1%的水平上显著。
(iv)faminc和hhsize联合显著吗?
(v)第(iii)部分中价格变量系数的符号与你的预期一致吗?请解释。
(vi)令β1和β2为ecoprc和regprc的系数,相对一个双侧备择假设,检验假设H0:-β1=β2。报告检验的p值。(如果你的回归软件不能很容易地计算这种检验,你可能还要参考教材4.4节
(vii)对样本中的所有观测求E(ecolbslx)的估计值[见方程(17.25)],称之为ecolbsi。最大和最小拟合值是多少?
(viii)计算ecolbs,和ecolbsi之相关系数的平方。
(ix)现在,利用第(iii)部分中同样的解释变量,估计ecolbs的一个线性模型。为什么OLS估计值比托宾估计值小那么多?从拟合优度来看,托宾模型比线性模型更好吗?
(x)评价如下命题:“由于托宾模型的R,如此之小,所以估计的价格效应可能是不一致的。”
以下关于黑盒测试用例设计方法的叙述,错误的是()。
A.边界值分析通过选择等价类边界作为测试用例,不仅重视输入条件边界,而且也必须考虑输出域边界 B.因果图方法是从用自然语言书写的程序规格说明的描述中找出因(输入条件)和果(输出或程序状态的改变),可以通过因果图转换为判定表 C.正交试验设计法,就是使用已经造好了的正交表格来安排试验并进行数据分析的一种方法,目的是用最少的测试用例达到最高的测试覆盖率 D.等价类划分法根据软件的功能说明,对每一个输入条件确定若干个有效等价类和无效等价类,但只能为有效等价类设计测试用例
●以下关于软件测试原则的叙述中,不正确的是(56)。
A.测试用例不仅选用合理的输入数据,还要选择不合理的输入数据
B.应制定测试计划并严格执行,排除随意性
C.对发现错误较多的程序段,应进行更深入的测试
D.程序员应尽量测试自己的程序
散装货物运输的运费比集装箱运费低,其装卸费用在总运费中的比例()。
A.小
B.大
C.随机变化
D.相同

















