题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
(β分布) 随机变量 X的密度函数为其中a>0 ,β>0 ,都是常数,试求:(1)系数A(2)EX,DX
(β分布) 随机变量 X的密度函数为
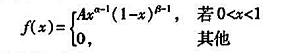
其中a>0 ,β>0 ,都是常数,试求:
(1)系数A
(2)EX,DX
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
(β分布) 随机变量 X的密度函数为
其中a>0 ,β>0 ,都是常数,试求:
(1)系数A
(2)EX,DX
如果结果不匹配,请 联系老师 获取答案
 更多“(β分布) 随机变量 X的密度函数为其中a>0 ,β>0 ,…”相关的问题
更多“(β分布) 随机变量 X的密度函数为其中a>0 ,β>0 ,…”相关的问题
已定义好函数f(n),其中n为形参。若以实参为m调用该函数并将返回的函数值赋给变量X,以下写法正确的是()。
A)x=f(n)
B)x=Call f(n)
C)x=f(m)
D)x=Call f(m)
有一个类A,下面为其构造函数的声明,其中正确的是 ()
A.void A(int x){…}
B.A(int x){…}
C.a(int x){…}
D.void a(int x){…}
令关系模式R=S(U;F),其中U为属性集,F为函数依赖集。假设U=X、Y、Z为3个不可分解的不同属性,若F={XY→Z,YZ→X),则R保持依赖的关系模式分解,一般只能分解到______。
A.1NF
B.2NF
C.3NF
D.BCNF
A.Y→Z成立,则X→Z
B.X→Z成立,则X→YZ
C.ZU成立,则X→YZ
D.WY→Z成立,则XW→Z
请编写函数fun(),其功能是:计算并输出给定10个数的方差。
.jpg)
其中
.jpg)
例如,给定的10个数为95.0,89.0,76.0,65.0,88.0, 72.0,85.0,81.0,90.0,56.0,则输出为S=11.730729。
注意;部分源程序给出如下.
请勿改动主函数mam和其他函数中的任何内容,仅在函数fun的花括号中填入所编写的若干语句。
试题程序:
include<math.h>
include<stdio.h>
double fun(double x[10])
{
}
main()
{
double s,x[i0]={95.0,89.0,76.0,65.0,
88.0,72.0,85.0,81.0,90.0,56.0};
int i;
printf("\nThe original data is:\n");
for(i=0;i<10;i++)
printf("%6.1f ",x[i]);
printf("\n\n ");
s=fun(x);
printf("s=%f\n\n ",s);
}
A.x=f(n)
B.x=Call f(n)
C.x=f(m)
D.x=Call f(m)
根据关系模型中数据间的函数依赖关系,关系模式可分成多种不同的范式(NP),其中,第二范式排除了关系模式中非主属性对键的(16)函数依赖;第三范式排除了关系式中非主属性对键的(17)函数依赖。令关系模式R=S(U;F),其中U为属性集,F为函数依赖集,假设U=XYZ为三个不可分解的不同属性,那么若F;{X→Y,Y→Z},则R是(18)。若F ={XY→Z,YZ→X),则R保持依赖的关系模式分解,一般只能分解到(19)。
A.传递
B.非传递
C.完全
D.部分
某程序每获得一对随机数(x,y),都判断x2+y2≤1是否成立。如果N对随机数中,有m对满足这个不等式,则当N足够大时,数值m/N将会比较接近(57)。
A.必然有一半数小于1/2,有一半数大于1/2
B.大致顺序、等间隔地排列于(0,1)之间
C.其中落在任意子区间(a,b)中的数的比率大致接近于b-a
D.从小到大排序后,各个数都分别位于(0,1)的Ⅳ等分子区间内