 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
试设计一个后缀数组类、用倍前缀算法构造后缀数组,并支持以下运算:(1)length()返回后缀数组长度.(2)select(inti)返回sa[i].(3)index(inti)返问rank[i].(4)llep(inti)返回lcp[i].
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“试设计一个后缀数组类、用倍前缀算法构造后缀数组,并支持以下运…”相关的问题
更多“试设计一个后缀数组类、用倍前缀算法构造后缀数组,并支持以下运…”相关的问题
在数据压缩编码的应用中,哈夫曼(Huffman)算法可以用来构造具有(18)的二叉树,这是一种采用了(19)的算法。
A.前缀码
B.最优前缀码
C.后缀码
D.最优后缀码
阅读以下预备知识、函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【预备知识】
①对给定的字符集合及相应的权值,采用哈夫曼算法构造最优二叉树,并用结构数组存储最优二叉树。例如,给定字符集合{a,b,c,d}及其权值2、7、4、5,可构造如图3所示的最优二叉树和相应的结构数组Ht(数组元素Ht[0]不用)(见表5)。
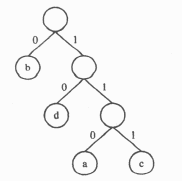
图3最优二叉树
表5 结构数组Ht
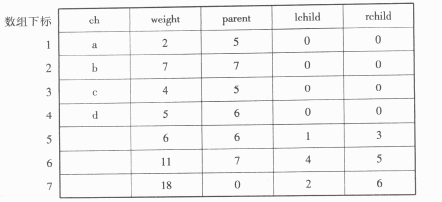
结构数组Ht的类型定义如下:
define MAXLEAFNUM 20
struct node{
char ch;/*当前结点表示的字符,对于非叶子结点,此域不用*/
int weight;/*当前结点的权值*/
int parent;/*当前结点的父结点的下标,为0时表示无父结点*/
int lchild,rchild;
/*当前结点的左、右孩子结点的下标,为0时表示无对应的孩子结点*/
}Ht[2*MAXLEAFNUM];
②用′0′或′1′标识最优二叉树中分支的规则是:从一个结点进入其左(右)孩子结点,就用′0′(′1′)标识该分支(示例如图3所示)。
③若用上述规则标识最优二叉树的每条分支后,从根结点开始到叶子结点为止,按经过分支的次序,将相应标识依次排列,可得到由′0′、′1′组成的一个序列,称此序列为该叶子结点的前缀编码。例如图3所示的叶子结点a、b、c、d的前缀编码分别是110、0、111、10。
【函数5.1说明】
函数void LeafCode(int root,int n)的功能是:采用非递归方法,遍历最优二叉树的全部叶子结点,为所有的叶子结点构造前缀编码。其中形参root为最优二叉树的根结点下标;形参n为叶子结点个数。
在构造过程中 ,将Ht[p].weight域用作被遍历结点的遍历状态标志。
【函数5.1】
char**Hc;
void LeafCode(int root,int n)
{/*为最优二叉树中的n个叶子结点构造前缀编码,root是树的根结点下标*/
int i,p=root,cdlen=0;char code[20];
Hc=(char**)malloc((n+1)*sizeof(char*));/*申请字符指针数组*/
for(i=1;i<=p;++i)
Ht[i].weight=0;/*遍历最优二叉树时用作被遍历结点的状态标志*/
while(p){/*以非递归方法遍历最优二叉树,求树中每个叶子结点的编码*/
if(Ht[p].weight==0){/*向左*/
Ht[p].weight=1;
if (Ht[p].lchild !=0) { p=Ht[p].lchild; code[cdlen++]=′0′;}
else if (Ht[p].rchild==0) {/*若是叶子结 点,则保存其前缀编码*/
Hc[p]=(char*)malloc((cdlen+1)*sizeof(char));
(1) ;strcpy(He[p],code);
}
}
else if (Ht[p].weight==1){/*向右*/
Ht[p].weight=2;
if(Ht[p].rchild !=0){p=Ht[p].rchild;code[cdlen++]=′1′;}
}
else{/*Ht[p].weight==2,回退*/
Ht[p].weight=0;
p= (2) ; (3) ;/*退回父结点*/
}
}/*while结束*/
}
【函数5.2说明】
函数void Decode(char*buff,int root)的功能是:将前缀编码序列翻译成叶子结点的字符序列并输出。其中形参root为最优二叉树的根结点下标;形参buff指向前缀编码序列。
【函数5.2】
void Decode(char*buff,int root)
{ int pre=root,p;
while(*buff!=′\0′){
p=root;
while(p!=0){/*存在下标为p的结点*/
pre=p;
if((4) )p=Ht[p].lchild;/*进入左子树*/
else p=Ht[p].rchild;/*进入右子树*/
buff++;/*指向前缀编码序列的下一个字符*/
}
(5) ;
printf(″%c″,Ht[pre].ch);
}
}
【问题 1】 (7 分〉 小张跟着指导教师对一个软件模块进行测试。为了完成这个测试,指导教师设计了 辅助模块去模拟与被测模块相关的其他模块。其中(1 )模块用于模拟被测试模块的上一级模块,相当于被测模块的主程序,(2 ) 模块用于模拟被测模块工作过程中所调用的模块。 在这个模块的测试中,小张设计测试用例完成了模块测试 5 个方面的任务,其中; (3)是对数据类型说明、初始化、默认值等方面的问题进行测试,并测试全局数据对模块的影响; (4)能够发现由于计算错误、不正确的判定或不正常的控制流而产生的错误; (5)主要是对参数表、调用子模块的参数、全局变量、文件I/O操作进行测试; (6)是检查模块在工作中发生了错误,其中的出错处理设施是否有效: (7)检查在限制数据处理而设置的边界处,测试模块是否能够正常工作。 【问题 2 】 (3 分〉 在集成测试中,小张采用增量式集成测试法,在自顶向下集成方式的广度优先策略中,如图 3-1 模块结构的广度优先顺序为(8)。集成测试过程有两个重要的里程碑,它们是(9)、 (10)。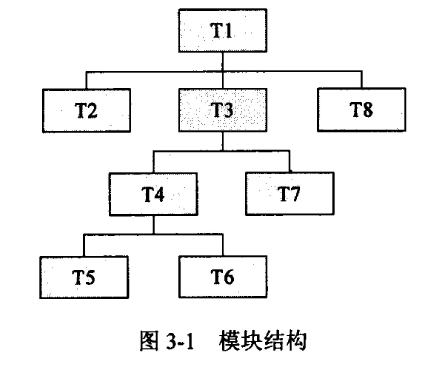 【问题 3】(5分) 软件系统中关于电话号码是这样设定的:电话号码由地区码、前缀和后缀 3 部分组成。地区码由空白或 4 位数字组成;前缀是非 "0" 或非 "1" 开头的 3 位数字:后缀是4 位数字。测试小组设计了等价类,如表 3-1 所示。请根据题目说明及表 3-1 ,填补空(11)~(15)。 表 3-1 电话号码输入等价类表
【问题 3】(5分) 软件系统中关于电话号码是这样设定的:电话号码由地区码、前缀和后缀 3 部分组成。地区码由空白或 4 位数字组成;前缀是非 "0" 或非 "1" 开头的 3 位数字:后缀是4 位数字。测试小组设计了等价类,如表 3-1 所示。请根据题目说明及表 3-1 ,填补空(11)~(15)。 表 3-1 电话号码输入等价类表
论述题1:以下是某应用程序的规格描述,请按要求回答问题
程序规则:实现某城市的电话号码,该电话号码由三部分组成。它的说明如下:区号空白或3位数字;前缀非“0”或“1”开头的3位数字;后缀4位数字。
(1)请分析该程序的规则说明和被测程序的功能
(2)采用等价类划分方法设计测试用例。
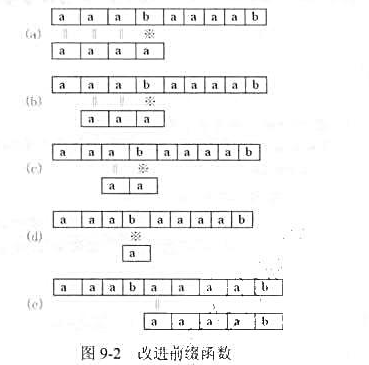
在图9-2(a)中匹配失败后,按前缀函数指示继续作了图(b)~(d)的比较后,最后在图(e)找到一个匹配.事实上,图(b)~(d)的比较都是多余的.因为模式串在位置0、1、2处的字符和位置3处的字符都相等,因此不需要再和主串中位置3处的字符比较,而可以将模式一次向右滑动4个字符,直接进入图(e)的比较.这就是说,在KMP算法中遇到p[j+1]≠t[i],且p[j+1]=p[next[j]+1]时,可一次向右滑动j-next[next[j]]个字符,而不是j-next[j]个字符.根据此观察,设计一个改进的前缀函数,使得遇到上述特殊情况时效率更高.
阅读以下说明和C++ 程序,将应填入(n)处的字句写在对应栏内。
[说明]
试从含有n个int 型数的数组中删去若干个成分,使剩下的全部成分构成一个不减的子序列。设计算法和编写程序求出数组的不减子序列的长。
[C++ 程序]
include<stdio.h>
define N 100
int b[]={9,8,5,4,3,2,7,6,8,7,5,3,4,5,9,1};
int a [N];
define n sizeofb/sizeofb[0]
void main ()
{
kit k,i,j;
(1)
(2)
for (i=1;i<n; i++ )
{
for (j=k;(3); j--);
(4); /*长为 j+1 的子序列的终元素存储在 a[j+1]*/
if ((5)k++; /*最长不减子序列长 k 增1*/
}
printf ("K = %d\n ",k );
}
在一个用数组实现的队列类中,假定数组长度为MS,队首元素位置为first,队列长度为length,则队首的后一个位置为()。
A.first+1
B.(first+1)%MS
C.(first-1)%MS
D.(first+length)%MS
A.length+1
B.first+length
C.(first+length-1)%MS
D.(first+length)%MS
A.一串IP地址
B.一串自治系统编号
C.一串路由编号
D.一串字网地址

















