 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
HDFS专为解决大数据存储问题而产生的,其具备了强大的跨平台兼容性,支持批和流数据读写,实现了低延时数据访问,并兼容廉价的硬件设备。()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“HDFS专为解决大数据存储问题而产生的,其具备了强大的跨平台…”相关的问题
更多“HDFS专为解决大数据存储问题而产生的,其具备了强大的跨平台…”相关的问题
A.Hive元数据存储独立于数据存储之外,从而解耦合元数据和数据,灵活性高,二传统数据仓库数据应用单一,灵活性低
B.Hive基于HDFS存储,理论上存储可以无限扩容,而传统数据仓库存储量有上限
C.由于Hive的数据存储在HDFS上,所以可以保证数据的高容错,高可靠
D.由于Hive基于大数据平台,所以查询效率比传统数据仓库快
A.容易修改数据问题
B.加快数据传输速度
C.保证数据的可靠性
D.容易检查数据错误
试题二(共25分)
阅读以下关于分布式存储系统设计的叙述,回答问题1至问题3。
某软件公司开发基于云计算的分布式文档协作平台(DDCP),系统部分需求如下所示:
(1)实现文档的分布式存储,客户端可随时随地上传和下载文档;
(2)支持多客户端并发编辑同一文档,某个客户端所做修改会实时显示在其他客户端;
(3)要求系统具有自我修复机制,当系统中某个节点失效时,无需人工干预能够自动实现节点替换并恢复到一致状态。
项目组经过讨论,决定采用现有的分布式文件系统作为基础架构,但在具体选用哪种设计方案时产生了分歧。王工建议采用Hadoop分布式文件系统HDFS作为系统参考架构,但张工认为Google分布式文件系统GFS更适合该系统需求。最后经过更为详细
的分析和讨论,同意了张工的建议,采用GFS作为分布式文档协作平台的文件系统架构。
【问题1】(12分)
请用300字以内的文字说明GFS和HDFS有何异同,并针对系统需求,用200字以内的文字说明选择GFS的原因。
【问题2】(8分)
针对图2-1所示DDCP基础架构,请分别说明一次数据读操作和一次并发写操作的过程。
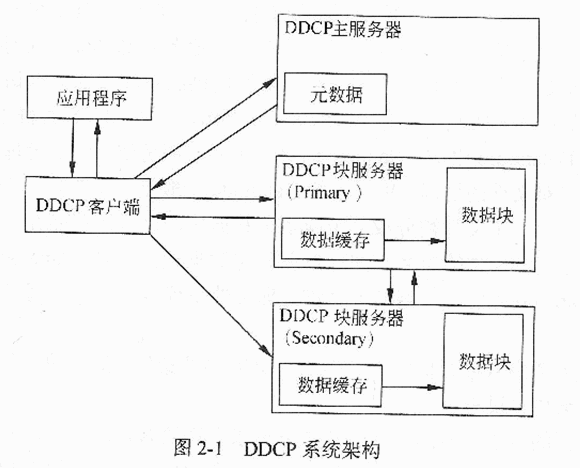
【问题3】(5分)
请分别叙述采用GFS和HDFS架构,单点失效问题是如何解决的。
简述数据仓库设计中的核心概念与实施的具体步骤。
HBase 依靠()存储底层数据
A HDFS
B Hadoop
C Memory
DMapReduce

















