 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在统计计算中,()算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。
A.K-Means算法
B.Apriori算法
C.最大期望算法
D.KNN算法
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.K-Means算法
B.Apriori算法
C.最大期望算法
D.KNN算法
如果结果不匹配,请 联系老师 获取答案
 更多“在统计计算中,()算法是在概率模型中寻找参数最大似然估计的算…”相关的问题
更多“在统计计算中,()算法是在概率模型中寻找参数最大似然估计的算…”相关的问题
(i)变量train是工作培训指标变量。样本中有多少人参与了工作培训项目?一个男人实际参加工作培训最多达几个月?
(ii)将train对unem74,unem75,age,educ,black,hisp和married等几个人口统计和培训前变量做一个线性回归。这些变量在5%的显著性水平上联合显著吗?
(iii)估计第(ii)部分中线性模型的一个概率单位形式。计算所有变量联合显著性的似然比检验。你得到什么结论?
(iv)基于第(ii)部分和第(iii)部分的答案,为解释1978年的失业状况,参与工作培训可视为外生变量吗?请解释。
(v)做unem78对train的简单回归,并以方程形式报告结果。估计参与工作培训项目对1978年失业的概率有何影响?它统计显著吗?
(vi)做unem78对train的概率单位模型。将train的概率单位系数与第(v)部分线性模型中得到的系数相比较有意义吗?
(vii)求出第(v)部分与第(vi)部分的拟合概率。解释它们为什么相同。为了度量工作培训项目的效果和统计显著性,你将采用哪个方法?
(viii)在第(v)部分与第(vi)部分模型中将第(ii)部分中的所有变量作为额外控制变量。现在拟合概率还相同吗?它们之间有何关系?
利用PNTSPRD.RAW中的数据。
(i)变量favwin是一个二值变量,在拉斯维加斯所押的球队胜出了预定的分数差时取值1。估计所押球队获胜概率的线性概率模型为
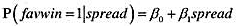
如果分数差包括了所有相关的信息,那我们预期β0=0.5。请解释。
(ii)用OLS估计第(i)部分的模型。相对于双侧备择假设检验H0:β0=0.5。同时使用通常的标准误和异方差一稳健的标准误。
(iii)spread在统计上显著吗?当spread=10时,被押球队获胜的估计概率是多少?
(iv)现在对P(favwin=Ilspread)估计一个概率单位模型。解释和检验截距项为0的虚拟假设。[提示:注意Φ(0)=0.5。]
(v)利用概率单位模型估计当spread=10时被押球队获胜的概率。并与第(iii)部分的LPM估计值相比较。
(vi)在概率单位模型中增加变量fuvhome、fav25和und25,并用似然比检验来检验这些变量的联合显著性。(x2分布中的自由度是多少?)解释这个结果,注意分数差是否包括了赛前可观测到的全部信息这个问题。

A.团体名
B.用户名ID
C.访问权限
D.访问控制
关于概率算法,下述说法中错误的是(15)。
A.数值概率算法所求得的往往是近似解,且精度随着计算时间的增长而不断提高,常用于数值计算
B.舍伍德算法能求得问题的一个解,但未必正确,正确的概率随着计算时间的增加而提高,通常用于求问题的精确解
C.若能用拉斯维加斯算法求得一个解,那么它一定正确,其找到解的概率也随着计算时间的增加而提高
D.蒙特卡罗算法的缺点就是无法有效地判断所求解的正确性
A.分类器的构造方法有统计方法、机器学习方法、神经网络方法等
B.有三种分类器评价或比较尺度:预测准确度、计算复杂度、模型描述的简洁度
C.统计方法包括决策树法和规则归纳法
D.神经网络方法主要是BP算法
在CSMA中,决定退让时间的算法为:
①如果信道空闲,以户的概率发送,而以(1-p)的概率延迟一个时间单位t;
②如果信道忙,继续监听直至信道空闲并重复步骤①;
③如果发送延迟了一个时间单位t,则重复步骤①。
上述算法为(14)。在该算法中重要的是如何选择概率p的值,p的取值首先考虑的是(15)。(16)时冲突不断增大,吞吐率会(17)。
A.1-坚持算法
B.P-坚持算法
C.非坚持算法
D.二进制指数后退算法
A.团体名
B.用户名ID
C.访问权限
D.访问控制
问题描述:设磁盘上有n个文件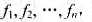 每个文件占用磁盘上的1个磁道.这n个文件的检索概率分别是
每个文件占用磁盘上的1个磁道.这n个文件的检索概率分别是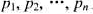 且
且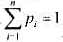 磁头从当前磁道移到被检信息磁道所需的时间可用这两个磁道之间的径向距离来度量.如果文件fi存放在第i(1≤i≤n)道上,则检索这n个文件的期望时间是
磁头从当前磁道移到被检信息磁道所需的时间可用这两个磁道之间的径向距离来度量.如果文件fi存放在第i(1≤i≤n)道上,则检索这n个文件的期望时间是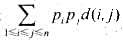 .式中,d(i,j)是第i道与第j道之间的径向距离|i-j|.
.式中,d(i,j)是第i道与第j道之间的径向距离|i-j|.
磁盘文件的最优存储问题要求确定这n个文件在磁盘上的存储位置,使期望检索时间达到最小.试设计一个解此问题的算法,并分析算法的正确性与计算复杂性.
算法设计:对于给定的文件检索概率,计算磁盘文件的最优存储方案.
数据输入:由文件input.txt给出输入数据.第1行是正整数n,表示文件个数.第2行有n个正整数a,表示文件的检索概率.实际上第k个文件的检索概率应为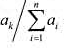
结果输出:将计算的最小期望检索时间输出到文件output.txt.

A.模型输入可以通过修改IR的xml文件实现输出类别的增减
B.通过计算softmax的值可以获得类别标签的概率/置信度
C.模型输出类别,不需要额外计算
D.通过np.argsort方法计算类别标签的概率
在CSMA中,决定退让时间的算法如下
(1)如果信道空闲,则以P的概率发送,而以1-P的概率延迟一个时间单位to
(2)如果信道忙,则继续监听直至信道空闲并重复步骤(1)。
(3)如果发送延迟了一个时间单位t,则重复步骤(1)。
上述算法为(7)。在该算法中重要的是如何选择概率P的值,P的取值首先考虑的是(8),如果(9),表明有多个站在同时试图发送,则冲突不可避免要发生。最坏的情况是冲突不断增大,吞吐率会(10)。
A.1-坚持型算法
B.P-坚持型算法
C.非坚持型算法
D.二进制指数后退算法

















