试题四(共15 分)
阅读下列说明和C代码,回答问题 1 至问题3,将解答写在答题纸的对应栏内。
【说明】
某应用中需要对100000 个整数元素进行排序,每个元素的取值在 0~5 之间。排序算法的基本思想是:对每一个元素 x,确定小于等于 x的元素个数(记为m),将 x放在输出元素序列的第m 个位置。对于元素值重复的情况,依次放入第 m-l、m-2、…个位置。例如,如果元素值小于等于4 的元素个数有 10 个,其中元素值等于 4 的元素个数有3个,则 4 应该在输出元素序列的第10 个位置、第 9 个位置和第8 个位置上。
算法具体的步骤为:
步骤1:统计每个元素值的个数。
步骤2:统计小于等于每个元素值的个数。
步骤3:将输入元素序列中的每个元素放入有序的输出元素序列。
【C代码】
下面是该排序算法的C语言实现。
(1)常量和变量说明
R:常量,定义元素取值范围中的取值个数,如上述应用中 R值应取6i:循环变量
n:待排序元素个数
a:输入数组,长度为n
b:输出数组,长度为n
c:辅助数组,长度为R,其中每个元素表示小于等于下标所对应的元素值的个数。
(2)函数sort
1 void sort(int n,int a[ ],intb[ ]){
2 int c[R],i;
3 for (i=0;i< (1) ;i++){
4 c[i]=0;
5 }
6 for(i=0;i<n;i++){
7 c[a[i]] = (2) ;
8 }
9 for(i=1;i<R;i++){
10 c[i]= (3) ;
11 }
12 for(i=0;i<n;i++){
13 b[c[a[i]]-1]= (4) ;
14 c[a[i]]=c[a[i] ]-1;
15 }
16 }
【问题1】(8 分)
根据说明和C代码,填充 C代码中的空缺(1)~(4)。
【问题2】(4 分)
根据C代码,函数的时间复杂度和空间复杂度分别为 (5) 和 (6) (用 O符号
表示)。
【问题3】(3 分)
根据以上C代码,分析该排序算法是否稳定。若稳定,请简要说明(不超过 100 字);
若不稳定,请修改其中代码使其稳定(给出要修改的行号和修改后的代码)。
从下列的2 道试题(试题五和试题六)中任选 1 道解答。
如果解答的试题数超过 道,则题号小的 道解答有效。
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
![问题描述:给定2个长度分别为n和m的序列x[0...n-1]和y[0...m-1],以及一个长度为p](https://img2.soutiyun.com/ask/2021-01-05/97870096903162.png)
![问题描述:给定2个长度分别为n和m的序列x[0...n-1]和y[0...m-1],以及一个长度为p](https://img2.soutiyun.com/ask/2021-01-05/978700980362268.png)

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“问题描述:给定2个长度分别为n和m的序列x[0...n-1]…”相关的问题
更多“问题描述:给定2个长度分别为n和m的序列x[0...n-1]…”相关的问题
 .m处理器问题要求的是
.m处理器问题要求的是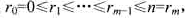 ,将数据包序列划分为m段:
,将数据包序列划分为m段: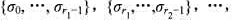
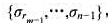 使
使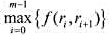 达到最小.式中,
达到最小.式中,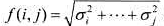 是序列
是序列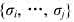 的负载量.
的负载量.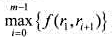 的最小值称为数据包序列
的最小值称为数据包序列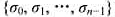 的均衡负载量.
的均衡负载量.

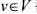 都有权值w(v).如果
都有权值w(v).如果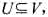 ,且对任意(u,V)∈E有u∈U或v∈U,就称U为图G的一个顶点覆盖.G的最小权顶点覆盖是指G中所含顶点权之和最小的顶点覆盖.
,且对任意(u,V)∈E有u∈U或v∈U,就称U为图G的一个顶点覆盖.G的最小权顶点覆盖是指G中所含顶点权之和最小的顶点覆盖.

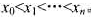 .有向直线L上的每个点x都有权值w(xi),每条有向边
.有向直线L上的每个点x都有权值w(xi),每条有向边 都有一个非负边长
都有一个非负边长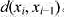 .有向直线L上的每个点x可以看作客户,其服务需求量为w(xi)e每条边
.有向直线L上的每个点x可以看作客户,其服务需求量为w(xi)e每条边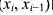 的边长
的边长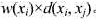 .在点x0处已设置了服务机构,现在要在直线L上增设2处服务机构,使得整体服务转移费用最小.
.在点x0处已设置了服务机构,现在要在直线L上增设2处服务机构,使得整体服务转移费用最小.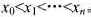 接下来的n行中,每行有2个整数.第i+1行的2个整数分别表示
接下来的n行中,每行有2个整数.第i+1行的2个整数分别表示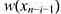 和
和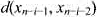 .
.
















