 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
从待排序的序列中任取一个结点作为关键码,采用交换方法使该值某一边的数为大于等于它的数,另一边为小于等于它的数,再分别对左右两边采取同样方法,这种排序方法称为 ()。
A.冒泡排序
B.堆排序
C.基数排序
D.快速排序
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.冒泡排序
B.堆排序
C.基数排序
D.快速排序
如果结果不匹配,请 联系老师 获取答案
 更多“从待排序的序列中任取一个结点作为关键码,采用交换方法使该值某…”相关的问题
更多“从待排序的序列中任取一个结点作为关键码,采用交换方法使该值某…”相关的问题
从供选择的答案中选出应填入下列叙述中()内的正确答案:
堆是一种有用的数据结构。例如关键码序列(A) 是一个堆。
堆排序是一种(B) 排序,它的一个基本问题是如何建堆,常用的建堆算法是1964年 Floyd提出的(C) 。对含n个元素的序列进行排序时,堆排序的时间复杂性是(D) ,所需的附加存储结点是(E)。
供选择的答案
A:①16,72,31,23,94,53
②94,53,31,72,16,53
③16,53,23,94,31,?2
④16,31,23,94,53,72
⑤94,11,53,23,16,72
B:①插入 ②选择 ③交换 ④基数 ⑤归并
C:①淘汰法 ②筛选法 ③递推法 ④LRU算法
D、E:①O(nlog2n) ②O(n) ③O(log2n)
④O(n2) ⑤O(1)
(40)
A.从根结点到任何一个叶子结点的路径上,结点的关键码序列呈递增排列
B.从根结点到任何一个叶子结点的路径上,结点的关键码序列呈递减排列
C.同层次结点从左向右排列,结点的关键码序列呈递增排列
D.同层次结点从左向右排列,结点的关键码序列呈递减排列
从供选择的答案中选出应填入下列叙述中()内的正确答案:
在二叉排序树中,每个结点的关键码值(A),(B)一棵二叉排序树,即可得到排序序列。同一个结点集合,可用不同的二叉排序树表示,人们把平均检索长度最短的二叉排序树称做最佳二叉排序树,最佳二叉排序树在结构上的特点是(C)。
供选择的答案
A:①比左子树所有结点的关键码值大,比右子树所有结点的关键码值小
②比左子树所有结点的关键码值小,比右子树所有结点的关键码值大
③比左右子树的所有结点的关键码值大
④与左子树所有结点的关键码值和右子树所有结点的关键码值无必然的大小关系
B:①前序遍历 ②中序(对称)遍历
③后序遍历 ④层次遍历
C:①除最下二层可以不满外,其余都是充满的
②除最下一层可以不满外,其余都是充满的
③每个结点的左右子树的高度之差的绝对值不大于1
④最下层的叶子必须在左边
设有一个关键码的输入序列(55,31,11,37,46,73,63,02,07):
(1)从空树开始构造平衡二叉搜索树,画出每加入一个新结点时二叉树的形态。若发生不平衡,指明需进行的平衡旋转的类型及平衡旋转的结果
(2)计算该平衡二叉搜索树在等概率下的搜索成功的平均搜索长度和搜索不成功的平均搜索长度。
阅读下列函数说明和C代码,回答下面问题。
[说明]
冒泡排序算法的基本思想是:对于无序序列(假设扫描方向为从前向后,进行升序排列),两两比较相邻数据,若反序则交换,直到没有反序为止。一般情况下,整个冒泡排序需要进行众(1≤k≤n)趟冒泡操作,冒泡排序的结束条件是在某一趟排序过程中没有进行数据交换。若数据初态为正序时,只需1趟扫描,而数据初态为反序时,需进行n-1趟扫描。在冒泡排序中,一趟扫描有可能无数据交换,也有可能有一次或多次数据交换,在传统的冒泡排序算法及近年的一些改进的算法中[2,3],只记录一趟扫描有无数据交换的信息,对数据交换发生的位置信息则不予处理。为了充分利用这一信息,可以在一趟全局扫描中,对每一反序数据对进行局部冒泡排序处理,称之为局部冒泡排序。
局部冒泡排序的基本思想是:对于N个待排序数据组成的序列,在一趟从前向后扫描待排数据序列时,两两比较相邻数据,若反序则对后一个数据作一趟前向的局部冒泡排序,即用冒泡的排序方法把反序对的后一个数据向前排到适合的位置。扫描第—对数据对,若反序,对第2个数据向前冒泡,使前两个数据成为,有序序列;扫描第二对数据对,若反序,对第3个数据向前冒泡,使得前3个数据变成有序序列;……;扫描第i对数据对时,其前i个数据已成有序序列,若第i对数据对反序,则对第i+1个数据向前冒泡,使前i+1个数据成有序序列;……;依次类推,直至处理完第n-1对数据对。当扫描完第n-1对数据对后,N个待排序数据已成了有序序列,此时排序算法结束。该算法只对待排序列作局部的冒泡处理,局部冒泡算法的
名称由此得来。
以下为C语言设计的实现局部冒泡排序策略的算法,根据说明及算法代码回答问题1和问题2。
[变量说明]
define N=100 //排序的数据量
typedef struct{ //排序结点
int key;
info datatype;
......
}node;
node SortData[N]; //待排序的数据组
node类型为待排序的记录(或称结点)。数组SortData[]为待排序记录的全体称为一个文件。key是作为排序依据的字段,称为排序码。datatype是与具体问题有关的数据类型。下面是用C语言实现的排序函数,参数R[]为待排序数组,n是待排序数组的维数,Finish为完成标志。
[算法代码]
void Part-BubbleSort (node R[], int n)
{
int=0 ; //定义向前局部冒泡排序的循环变量
//暂时结点,存放交换数据
node tempnode;
for (int i=0;i<n-1;i++) ;
if (R[i].key>R[i+1].key)
{
(1)
while ((2) )
{
tempnode=R[j] ;
(3)
R[j-1]=tempnode ;
Finish=false ;
(4)
} // end while
} // end if
} // end for
} // end function
阅读下列函数说明和C代码,将应填入(n)处的字句写在的对应栏内。
A.归并排序
B.直接插入排序
C.直接选择排序
D.快速排序
下面是一个快速排序的逆归算法。为了避免最坏情况,取基准记录pivot采用从lelt,right和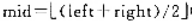 中取中间值,并交换到low位置的办法。数组A存放待排序的一组记录,数据类型为T,left和right是待排序子区间的最左端点和最右端点。
中取中间值,并交换到low位置的办法。数组A存放待排序的一组记录,数据类型为T,left和right是待排序子区间的最左端点和最右端点。

(1)实现三者取中子程序mediancy(A,left,right);
(2)改写QuickSort算法,不用栈消去第二个递归调用QuickSort(A,pivotPos+1,right);
(3)继续改写QuickSort算法,用栈消去剩下的递归调用。
设有关键码序列(Q,G,M,Z,A,N,B,P,X,H,Y,S,T,L,K,E),采用堆排序法进行排序,经过初始建堆后关键码值B在序列中的序号是()。
A)1
B)3
C)7
D)9

















