 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
首先访问结点的左子树,然后访问该结点,最后访问结点的右子树,这种遍历称为()。A.前序遍历B.后序遍
首先访问结点的左子树,然后访问该结点,最后访问结点的右子树,这种遍历称为 ()。
A.前序遍历
B.后序遍历
C.中序遍历
D.层次遍历
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
首先访问结点的左子树,然后访问该结点,最后访问结点的右子树,这种遍历称为 ()。
A.前序遍历
B.后序遍历
C.中序遍历
D.层次遍历
如果结果不匹配,请 联系老师 获取答案
 更多“首先访问结点的左子树,然后访问该结点,最后访问结点的右子树,…”相关的问题
更多“首先访问结点的左子树,然后访问该结点,最后访问结点的右子树,…”相关的问题
A.二叉树的遍历是指不重复地访问二叉树中的所有结点
B.二叉树的遍历允许重复地访问二叉树中的个别结点
C.在遍历二叉树的过程中,一般先遍历左子树,然后再遍历右子树
D.在先左后右的原则下,根据访问根结点的次序,二叉树的遍历可以分为三种:前序遍历、中序遍历、后序遍历
阅读下列函数说明和C函数,将应填入(n)处的字句写对应栏内。
[说明]
二叉树的二叉链表存储结构描述如下:
typedef struct BiTNode
{ datatype data;
struct BiTNode *lchild, * rchild; /*左右孩子指针*/
}BiTNode,* BiTree;
对二叉树进行层次遍历时,可设置一个队列结构,遍历从二叉树的根结点开始,首先将根结点指针入队列,然后从队首取出一个元素,执行下面两个操作:
(1) 访问该元素所指结点;
(2) 若该元素所指结点的左、右孩子结点非空,则将该元素所指结点的左孩子指针和右孩子指针顺序入队。
此过程不断进行,当队列为空时,二叉树的层次遍历结束。
下面的函数实现了这一遍历算法,其中Visit(datatype a)函数实现了对结点数据域的访问,数组queue[MAXNODE]用以实现队列的功能,变量front和rear分别表示当前队首元素和队尾元素在数组中的位置。
[函数]
void LevelOrder(BiTree bt) /*层次遍历二叉树bt*/
{ BiTree Queue[MAXNODE];
int front,rear;
if(bt= =NULL)return;
front=-1;
rear=0;
queue[rear]=(1);
while(front (2) ){
(3);
Visit(queue[front]->data); /*访问队首结点的数据域*/
if(queue[front]—>lchild!:NULL)
{ rear++;
queue[rear]=(4);
}
if(queue[front]->rchild! =NULL)
{ rear++;
queue[rear]=(5);
}
}
}
A.该结点双亲的序号为4
B.该结点处于二叉树的第4层
C.该结点没有右子树
D.该结点左子树根结点的序号为14
A.树中没有度为2的结点
B.树中只有一个根结点
C.树中非叶结点均只有左子树
D.树中非叶结点均只有右子树
有一个深度为4的满二叉树,下面关于序号为7的结点的叙述中,正确的是______。
A.该结点双亲的序号为4
B.该结点处于二叉树的第4层
C.该结点没有右子树
D.该结点左子树根结点的序号为14
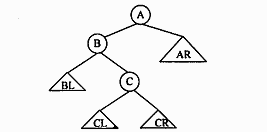
(61)
A. 以B 为根的子二叉树变为不平衡
B. 以C 为根的子二叉树变为不平衡
C. 以A 为根的子二叉树变为不平衡
D. 仍然是平衡二叉树
从供选择的答案中选出应填入下列叙述中()内的正确答案:
在二叉排序树中,每个结点的关键码值(A),(B)一棵二叉排序树,即可得到排序序列。同一个结点集合,可用不同的二叉排序树表示,人们把平均检索长度最短的二叉排序树称做最佳二叉排序树,最佳二叉排序树在结构上的特点是(C)。
供选择的答案
A:①比左子树所有结点的关键码值大,比右子树所有结点的关键码值小
②比左子树所有结点的关键码值小,比右子树所有结点的关键码值大
③比左右子树的所有结点的关键码值大
④与左子树所有结点的关键码值和右子树所有结点的关键码值无必然的大小关系
B:①前序遍历 ②中序(对称)遍历
③后序遍历 ④层次遍历
C:①除最下二层可以不满外,其余都是充满的
②除最下一层可以不满外,其余都是充满的
③每个结点的左右子树的高度之差的绝对值不大于1
④最下层的叶子必须在左边
A.非叶子结点只有左子树的二叉树
B.只有根结点的二叉树
C.根结点无右子树的二叉树
D.非叶子结点只有右子树的二叉树
(40)
A.从根结点到任何一个叶子结点的路径上,结点的关键码序列呈递增排列
B.从根结点到任何一个叶子结点的路径上,结点的关键码序列呈递减排列
C.同层次结点从左向右排列,结点的关键码序列呈递增排列
D.同层次结点从左向右排列,结点的关键码序列呈递减排列

















