

 如果结果不匹配,请
如果结果不匹配,请 
 更多“域名是从根到当前域所经过的所有结点的标记名,从【 】排列,并…”相关的问题
更多“域名是从根到当前域所经过的所有结点的标记名,从【 】排列,并…”相关的问题
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。[说明]
邻接表是图的一种顺序存储与链式存储结合的存储方法。其思想是:对于图G中的每个顶点 vi,将所有邻接于vi的顶点vj连成一个单链表,这个单链表就称为顶点vi的邻接表,其中表头称作顶点表结点VertexNode,其余结点称作边表结点EdgeNode。将所有的顶点表结点放到数组中,就构成了图的邻接表AdjList。邻接表表示的形式描述如下: define MaxVerNum 100 /*最大顶点数为100*/
typedef struct node{ /*边表结点*/
int adjvex; /*邻接点域*/
struct node *next; /*指向下一个边表结点的指针域*/ }EdgeNode;
typedef struct vnode{ /*顶点表结点*/
int vertex; /*顶点域*/
EdgeNode *firstedge; /*边表头指针*/
}VertexNode;
typedef VertexNode AdjList[MaxVerNum]; /*AdjList是邻接表类型*/
typedef struct{
AdjList adjlist; /*邻接表*/
int n; /*顶点数*/
}ALGraph; /*ALGraph是以邻接表方式存储的图类型*/
深度优先搜索遍历类似于树的先根遍历,是树的先根遍历的推广。
下面的函数利用递归算法,对以邻接表形式存储的图进行深度优先搜索:设初始状态是图中所有顶点未曾被访问,算法从某顶点v出发,访问此顶点,然后依次从v的邻接点出发进行搜索,直至所有与v相连的顶点都被访问;若图中尚有顶点未被访问,则选取这样的一个点作起始点,重复上述过程,直至对图的搜索完成。程序中的整型数组visited[]的作用是标记顶点i是否已被访问。
[函数]
void DFSTraverseAL(ALGraph *G)/*深度优先搜索以邻接表存储的图G*/
{ int i;
for(i=0;i<(1);i++) visited[i]=0;
for(i=0;i<(1);i++)if((2)) DFSAL(G,i);
}
void DFSAL(ALGraph *G,int i) /*从Vi出发对邻接表存储的图G进行搜索*/
{ EdgeNode *p;
(3);
p=(4);
while(p!=NULL) /*依次搜索Vi的邻接点Vj*/
{ if(! visited[(5)]) DFSAL(G,(5));
p=p->next; /*找Vi的下一个邻接点*/
}
}
阅读以下预备知识、函数说明和C代码,将应填入(n)处的字句写在答题纸的对应栏内。
【预备知识】
①对给定的字符集合及相应的权值,采用哈夫曼算法构造最优二叉树,并用结构数组存储最优二叉树。例如,给定字符集合{a,b,c,d}及其权值2、7、4、5,可构造如图3所示的最优二叉树和相应的结构数组Ht(数组元素Ht[0]不用)(见表5)。
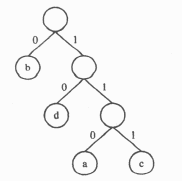
图3最优二叉树
表5 结构数组Ht
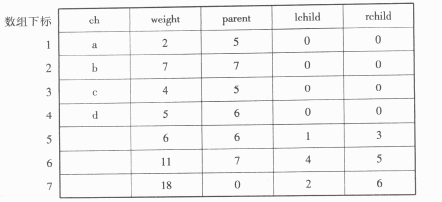
结构数组Ht的类型定义如下:
define MAXLEAFNUM 20
struct node{
char ch;/*当前结点表示的字符,对于非叶子结点,此域不用*/
int weight;/*当前结点的权值*/
int parent;/*当前结点的父结点的下标,为0时表示无父结点*/
int lchild,rchild;
/*当前结点的左、右孩子结点的下标,为0时表示无对应的孩子结点*/
}Ht[2*MAXLEAFNUM];
②用′0′或′1′标识最优二叉树中分支的规则是:从一个结点进入其左(右)孩子结点,就用′0′(′1′)标识该分支(示例如图3所示)。
③若用上述规则标识最优二叉树的每条分支后,从根结点开始到叶子结点为止,按经过分支的次序,将相应标识依次排列,可得到由′0′、′1′组成的一个序列,称此序列为该叶子结点的前缀编码。例如图3所示的叶子结点a、b、c、d的前缀编码分别是110、0、111、10。
【函数5.1说明】
函数void LeafCode(int root,int n)的功能是:采用非递归方法,遍历最优二叉树的全部叶子结点,为所有的叶子结点构造前缀编码。其中形参root为最优二叉树的根结点下标;形参n为叶子结点个数。
在构造过程中 ,将Ht[p].weight域用作被遍历结点的遍历状态标志。
【函数5.1】
char**Hc;
void LeafCode(int root,int n)
{/*为最优二叉树中的n个叶子结点构造前缀编码,root是树的根结点下标*/
int i,p=root,cdlen=0;char code[20];
Hc=(char**)malloc((n+1)*sizeof(char*));/*申请字符指针数组*/
for(i=1;i<=p;++i)
Ht[i].weight=0;/*遍历最优二叉树时用作被遍历结点的状态标志*/
while(p){/*以非递归方法遍历最优二叉树,求树中每个叶子结点的编码*/
if(Ht[p].weight==0){/*向左*/
Ht[p].weight=1;
if (Ht[p].lchild !=0) { p=Ht[p].lchild; code[cdlen++]=′0′;}
else if (Ht[p].rchild==0) {/*若是叶子结 点,则保存其前缀编码*/
Hc[p]=(char*)malloc((cdlen+1)*sizeof(char));
(1) ;strcpy(He[p],code);
}
}
else if (Ht[p].weight==1){/*向右*/
Ht[p].weight=2;
if(Ht[p].rchild !=0){p=Ht[p].rchild;code[cdlen++]=′1′;}
}
else{/*Ht[p].weight==2,回退*/
Ht[p].weight=0;
p= (2) ; (3) ;/*退回父结点*/
}
}/*while结束*/
}
【函数5.2说明】
函数void Decode(char*buff,int root)的功能是:将前缀编码序列翻译成叶子结点的字符序列并输出。其中形参root为最优二叉树的根结点下标;形参buff指向前缀编码序列。
【函数5.2】
void Decode(char*buff,int root)
{ int pre=root,p;
while(*buff!=′\0′){
p=root;
while(p!=0){/*存在下标为p的结点*/
pre=p;
if((4) )p=Ht[p].lchild;/*进入左子树*/
else p=Ht[p].rchild;/*进入右子树*/
buff++;/*指向前缀编码序列的下一个字符*/
}
(5) ;
printf(″%c″,Ht[pre].ch);
}
}
A.根域名服务器的地址和其父结点服务器地址
B.根域名服务器的地址和其子结点服务器地址
C.所有域名服务器的IP地址
D.所有域名服务器的域名
中从任一结点出发到根的路径上,所经过的结点序列必按其关键字降序排列。
A.二叉排序树
B.大顶堆
C.小顶堆
D.最优二叉树
从二叉树的任一结点出发到根的路径上,所经过的结点序列必按其关键字降序排列。
A.二叉排序树
B.大顶堆
C.小顶堆
D.平衡二叉树
A.公钥到私钥
B.变量域到C函数域
C.定义域到C函数域
D.定义域到C值域
(25)
A.公钥到私钥
B.变量域到 C 函数域
C.定义域到 C 函数域
D.定义域到 C 值域
阅读下列函数说明和C函数,将应填入(n)处的字句写对应栏内。
[说明]
二叉树的二叉链表存储结构描述如下:
typedef struct BiTNode
{ datatype data;
struct BiTNode *lchild, * rchild; /*左右孩子指针*/
}BiTNode,* BiTree;
对二叉树进行层次遍历时,可设置一个队列结构,遍历从二叉树的根结点开始,首先将根结点指针入队列,然后从队首取出一个元素,执行下面两个操作:
(1) 访问该元素所指结点;
(2) 若该元素所指结点的左、右孩子结点非空,则将该元素所指结点的左孩子指针和右孩子指针顺序入队。
此过程不断进行,当队列为空时,二叉树的层次遍历结束。
下面的函数实现了这一遍历算法,其中Visit(datatype a)函数实现了对结点数据域的访问,数组queue[MAXNODE]用以实现队列的功能,变量front和rear分别表示当前队首元素和队尾元素在数组中的位置。
[函数]
void LevelOrder(BiTree bt) /*层次遍历二叉树bt*/
{ BiTree Queue[MAXNODE];
int front,rear;
if(bt= =NULL)return;
front=-1;
rear=0;
queue[rear]=(1);
while(front (2) ){
(3);
Visit(queue[front]->data); /*访问队首结点的数据域*/
if(queue[front]—>lchild!:NULL)
{ rear++;
queue[rear]=(4);
}
if(queue[front]->rchild! =NULL)
{ rear++;
queue[rear]=(5);
}
}
}
试题四(共15分)
阅读下列说明和c代码,将应填入(n)处的字句写在答题纸的对应栏内。
【说明】
设某一机器由n个部件组成,每一个部件都可以从m个不同的供应商处购得。供应商j供应的部件i具有重量Wij和价格Cij。设计一个算法,求解总价格不超过上限cc的最小重量的机器组成。
采用回溯法来求解该问题:
首先定义解空间。解空间由长度为n的向量组成,其中每个分量取值来自集合{l,2,…,m},将解空间用树形结构表示。
接着从根结点开始,以深度优先的方式搜索整个解空间。从根结点开始,根结点成为活结点,同时也成为当前的扩展结点。向纵深方向考虑第一个部件从第一个供应商处购买,得到一个新结点。判断当前的机器价格(C11)是否超过上限(cc),重量(W11)是否比当前已知的解(最小重量)大,若是,应回溯至最近的一个活结点;若否,则该新结点成为活结点,同时也成为当前的扩展结点,根结点不再是扩展结点。继续向纵深方向考虑第二个部件从第一个供应商处购买,得到一个新结点。同样判断当前的机器价格(C11+C21)是否超过上限(cc),重量(W11+W21)是否比当前已知的解(最小重量)大。若是,应回溯至最近的一个活结点;若否,则该新结点成为活结点,同时也成为当前的扩展结点,原来的结点不再是扩展结点。以这种方式递归地在解空间中搜索,直到找到所要求的解或者解空间中已无活结点为止。
【C代码】
下面是该算法的C语言实现。
(1)变量说明
n:机器的部件数
m:供应商数
cc:价格上限
w[][]:二维数组,w[i][j]表示第j个供应商供应的第i个部件的重量
c[][]:二维数组,c[i][j]表示第j个供应商供应的第i个部件的价格
best1W:满足价格上限约束条件的最小机器重量
bestC:最小重量机器的价格
bestX[].最优解,一维数组,bestX[i]表示第i个部件来自哪个供应商
cw:搜索过程中机器的重量
cp:搜索过程中机器的价格
x[]:搜索过程中产生的解,x[i]表示第i个部件来自哪个供应商
i:当前考虑的部件,从0到n-l
j:循环变量
(2)函数backtrack
Int n=3;
Int m=3;
int cc=4:
int w[3][3]={{1,2,3},{3,2,1},{2,2,2}};
int c[3][3]={{1,2,3},{3,2,1},{2,2,2}};
int bestW=8;
int bestC=0;
int bestX[3]={0,0,0};
int cw=0;
int cp=0;
int x[3]={0,0,0};
int backtrack(int i){
int j=0;
int found=0;
if(i>n-1){/*得到问题解*/
bestW= cw;
bestC= cp;
for(j=0;j<n;j++){
(1)____;
}
return 1;
}
if(cp<=cc){/*有解*/
found=1;
}
for(j=0; (2)____;j++){
/*第i个部件从第j个供应商购买*/
(3) ;
cw=cw+w[i][j];
cp=cp+c[i][i][j];
if(cp<=cc && (4) {/*深度搜索,扩展当前结点*/
if(backtrack(i+1)){found=1;}
}
/*回溯*/
cw= cw -w[i][j];
(5) ;
}
return found;
}
从下列的2道试题(试题五和试题六)中任选1道解答。
如果解答的试题数超过1道,则题号小的1道解答有效。
















