 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
HDFS分布式存储集群的后台进程不包括()。
A.SecondaryNameNode
B.DataNode
C.JobTracker
D.NameNode
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.SecondaryNameNode
B.DataNode
C.JobTracker
D.NameNode
如果结果不匹配,请 联系老师 获取答案
 更多“HDFS分布式存储集群的后台进程不包括()。”相关的问题
更多“HDFS分布式存储集群的后台进程不包括()。”相关的问题
A.大文件分割成多个block存储
B.不支持一次写入、多次读取的访问模式
C.存储大文件,百MB,GB级文件
D.支持一次写入、多次读取的访问模式
A.HDFS:分布式文件系统,是Hadoop项目的两大核心之一,是谷歌GFS的开源实现
B.HBase:提供高可靠性、高性能、分布式的行式数据库,是谷歌Big Table的开源实现
C.Hive:一个基于Hadoop的数据仓库工具,用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储
D.Zookeeper:针对谷歌Chubby的一个开源实现,是高效可靠的协同工作系统
A.Hadoop是一个能够对大量数据进行分布式处理的软件框架
B.作为并行分布式计算平台,Hadoop采用分布式存储和分布式处理两大核心技术,能够高效地处理PB级数据
C.Hadoop只支持Java编程语言
D.Hadoop可以高效稳定地运行在廉价的计算机集群上,可以扩展到数以千计的计算机节点上
A.文件系统由本地文件系统向集群文件系统和分布式文件系统发展
B.传统NAS,面向PB级数据,复杂的卷管理及系统容量分配不均衡,会导致资源浪费
C.海量存储系统的特点是文件系统更复杂,管理更复杂
D.具有大规模扩展能力是海量存储系统的特点
试题二(共25分)
阅读以下关于分布式存储系统设计的叙述,回答问题1至问题3。
某软件公司开发基于云计算的分布式文档协作平台(DDCP),系统部分需求如下所示:
(1)实现文档的分布式存储,客户端可随时随地上传和下载文档;
(2)支持多客户端并发编辑同一文档,某个客户端所做修改会实时显示在其他客户端;
(3)要求系统具有自我修复机制,当系统中某个节点失效时,无需人工干预能够自动实现节点替换并恢复到一致状态。
项目组经过讨论,决定采用现有的分布式文件系统作为基础架构,但在具体选用哪种设计方案时产生了分歧。王工建议采用Hadoop分布式文件系统HDFS作为系统参考架构,但张工认为Google分布式文件系统GFS更适合该系统需求。最后经过更为详细
的分析和讨论,同意了张工的建议,采用GFS作为分布式文档协作平台的文件系统架构。
【问题1】(12分)
请用300字以内的文字说明GFS和HDFS有何异同,并针对系统需求,用200字以内的文字说明选择GFS的原因。
【问题2】(8分)
针对图2-1所示DDCP基础架构,请分别说明一次数据读操作和一次并发写操作的过程。
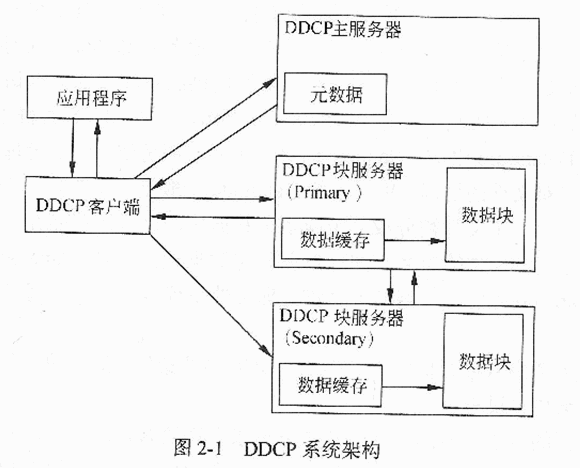
【问题3】(5分)
请分别叙述采用GFS和HDFS架构,单点失效问题是如何解决的。

















