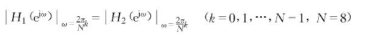阅读以下程序说明和C程序,将应填入(n)处的字句,写在对应栏内。
【程序说明】
某网络由n个端点组成,这些端点被物理地分成若干个分离的端点组。同一组内的两件端点i和j,它们或直接相连,或间接相连(端点i和端点j间接相连是指在这两件端点之间有一个端点相连序列,其中端点i和j分别与这相连序列中的某个端点直接相连)。网络的n个端点被统一编号为0,1,…,n-1。本程序输入所有直接相连的端点号对,分别求出系统各分离端点组中的端点号并输出。
程序根据输入的直接相连的两件端点号,建立n个链表,其中第i个链表的首指针为s[i],其结点是与端点i直接相连的所有端点号。
程序依次处理各链表。在处理s[i]链表中,用top工作链表重新构造s[i]链表,使s[i]链表对应系统中的一个端点组,其中结点按端点号从小到大连接。
【程序】
inelude
define N 100
typeef struct node{
int data;
struct node *link;
}NODE;
NODE * s[N];
int i,j,n,t;
NODE *q,*p,*x,*y,*top;
main()
{
printf(“Enter namber of components.”);
scanf(“%d”,&n);
for(i=0;i<n;i++) printf(“Enter pairs.\n”);
while(scanf(“%d%d”,&i,&j)==2)
{ /*输入相连端点对,生成相连端点结点链表*/
p=(NODE*)malloc(sizeof(NODE));
p→data=j;p→link=s[i];s[i]=p;
p=(NODE*)malloc(sizeof(NODE));
p→data=i;p→link=s[j];s[j]=p;
}
for(i=0;i<n;i++) /*顺序处理各链表*/
for(top=s[i], (1);top! =NULL;)
{ /*将第i链表移入top工作链表,并顺序处理工作链表的各结点*/
q=top;
(2);
if(s¨[j=q→data]!=NULL)
{ /将j链表也移入工作链表*/
for(p=s[j];p→link! =NULL;p= p→link);
p→link= top;top=s[j];
(3);
}
/*在重新生成的第i链表中寻找当前结点的插入点*/
for(y=s[i]; (4);x=y,y=y→link);
if(y!=NULL && y→data==q→data)
free(q); /*因重新生成的第i链表已有当前结点,当前结点删除*/
else{
(5);
if(y ==s[i])s[i]=q;
else x→link=q;
}
}
for(i =0;i < n;i++)
{/*输出结果*/
if(s[i]==NULL)continue;
for(p=s[i];p!=NULL;){
printf(“\t%d”,p→data);
q=p→link;free(p);p=q;
}
printf(“\n”);
}
}
 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“将某二元信源的输出序列分成长度都是7个符号的分组并给定一个(…”相关的问题
更多“将某二元信源的输出序列分成长度都是7个符号的分组并给定一个(…”相关的问题

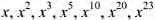 .可以证明,计算x23最少需要6次乘法.计算x23的幂序列中各幂次1、2、3、5、10、20、23组成了一个关于整数23的加法链.一般情况下,计算xn的幂序列中各幂次组成正整数n的一个加法链:
.可以证明,计算x23最少需要6次乘法.计算x23的幂序列中各幂次1、2、3、5、10、20、23组成了一个关于整数23的加法链.一般情况下,计算xn的幂序列中各幂次组成正整数n的一个加法链: