 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
若给定人类为个体域,解释P(x,y):x是y的父母;F(x):x是女性.试用通俗直白的语言明x和y在满足什么
若给定人类为个体域,解释P(x,y):x是y的父母;F(x):x是女性.试用通俗直白的语言明x和y在满足什么关系时下面公式为真.
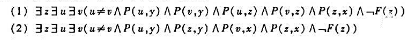
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
若给定人类为个体域,解释P(x,y):x是y的父母;F(x):x是女性.试用通俗直白的语言明x和y在满足什么关系时下面公式为真.
如果结果不匹配,请 联系老师 获取答案
 更多“若给定人类为个体域,解释P(x,y):x是y的父母;F(x)…”相关的问题
更多“若给定人类为个体域,解释P(x,y):x是y的父母;F(x)…”相关的问题
A.Y→Z成立,则X→Z
B.X→Z成立,则X→YZ
C.ZU成立,则X→YZ
D.WY→Z成立,则XW→Z
A.若 wx →y , y →Z 成立,则 X →Z 成立B.若 wx →y ,y →Z 成立,则 W →Z 成立C.若 X →y ,WY →z 成立,则 xw →Z 成立D. 若 X →y ,Z ⊆ U 成立,则 X →YZ 成立
文法G=(VT,VN,P,S)的类型由C中的(32)决定。若GO=({a,b},{S,X,Y},P,S),P中的产生式及其序号如下:
1:S→XaaY
2:X→Dqb
3:Y→XbXla
则GO为(33)型文法,对应于(34),由GO推导出句子aaaaa和baabbb时,所用产生式序号组成的序列分别为(35)和(36)。
A.VT
B.VN
C.P
D.S
若已定义x为int类型变量,说明指针变量p的正确语句是______。
A.int p=&x;
B.int*p=x;
C.int *p=&x;
D.*p=*x;
●文法G=(VT,VN,P,S)的类型由G中的 (32) 决定。若G0=({a,b},{S,X,Y},P,S),P中的产生式及其序号如下:
1:S→XaaY
2:X→YYlb
3:Y→XbXla
则G0为 (33) 型文法,对应于 (34) ,由G0推导出句子aaaaa和baabbb时,所用产生式序号组成的序列分别为 (35) 和 (36) 。
(32) A.VT
B.VN
C.P
D.S
(33) A.0
B.1
C.2
D.3
(34) A.图灵机
B.下推自动机
C.有限状态自动机
D.其他自动机
(35),(36) A.13133
B.12312
C.12322
D.12333
.jpg)
若某段程序所需指令或数据在Cache中取到的概率为P=0.5,则处理机X的存储器平均存取周期为(50)ms。假定指令执行时间与存储器的平均存取周期成正比,此时三个处理机执行该段程序由快到慢的顺序为(51)。
若P=0.65,则顺序为(52)。
若P=0.8,则顺序为(53)。
若P=0.85,则顺序为(54)。
A.0.2
B.0.48
C.0.52
D.0.6
请改正程序指定部位的错误,使它能得到正确结果。
[注意] 不要改动main函数,不得增行或删行,也不得更改程序的结构。
[试题源程序]
include<stdio.h>
include<stdlib.h>
typedef struct aa
{
int data;
struct aa *next;
}NODE;
fun(NODE *h)
{
int max=-1;
NODE *p;
/***********found************/
p=h;
while(p)
{
if(p->data>max)
max=p->data;
/************found************/
p=h->next;
}
return max;
}
outresult(int s, FILE *Pf)
{
fprintf(pf, "\nThe max in link: %d\n", s);
}
NODE *creatlink(int n, int m)
{
NODE *h, *p, *s, *q;
int i, x;
h=p=(NODE *)malloc(sizeof(NODE));
h->data=9999;
for(i=1; i<=n; i++)
{
s=(NODE *)malloc(sizeof(NODE));
s->data=rand()%m; s->next=p->next;
p->next=s; p=p->next;
}
p->next=NULL;
return h;
}
outlink(NODE *h, FILE *pf)
{
NODE *p;
p=h->next;
fprintf(Pf, "\nTHE LIST:\n\n HEAD");
while(P)
{
fprintf(pf, "->%d", P->datA); p=p->next;
}
fprintf(pf, "\n");
}
main()
{
NODE *head; int m;
head=cteatlink(12,100);
outlink(head, stdout);
m=fun(head);
printf("\nTHE RESULT"\n");
outresult(m, stdout);
}
若定义下列结构体,结构体变量p的出生年份赋值正确的语句是()。 struct st { int x; int y; int z; } struct worker { char name[20]; char sex; struct st birth; }p;
A.x=1987
B.birth.x=1987;
C.p.birth.x=1987;
D.p.x=1987;
阅读下列函数说明和C函数,将应填入(n)处的字句写在对应栏内。
[说明]
二叉树的二叉链表存储结构描述如下:
lypedef struct BiTNode
{ datatype data;
street BiTNode *lchiht, *rchild; /*左右孩子指针*/ } BiTNode, *BiTree;
下列函数基于上述存储结构,实现了二叉树的几项基本操作:
(1) BiTree Creale(elemtype x, BiTree lbt, BiTree rbt):建立并返回生成一棵以x为根结点的数据域值,以lbt和rbt为左右子树的二叉树;
(2) BiTree InsertL(BiTree bt, elemtype x, BiTree parent):在二叉树bt中结点parent的左子树插入结点数据元素x;
(3) BiTree DeleteL(BiTree bt, BiTree parent):在二叉树bt中删除结点parent的左子树,删除成功时返回根结点指针,否则返回空指针;
(4) frceAll(BiTree p):释放二叉树全体结点空间。
[函数]
BiTree Create(elemtype x, BiTree lbt, BiTree rbt) { BiTree p;
if ((p = (BiTNode *)malloc(sizeof(BiTNode)))= =NULL) return NULL;
p->data=x;
p->lchild=lbt;
p->rchild=rbt;
(1);
}
BiTree InsertL(BiTree bt, elemtype x,BiTree parent)
{ BiTree p;
if (parent= =NULL) return NULL;
if ((p=(BiTNode *)malloc(sizeof(BiTNode)))= =NULL) return NULL;
p->data=x;
p->lchild= (2);
p->rchild= (2);
if(parent->lchild= =NULL) (3);
else{
p->lchild=(4);
parent->lchild=p;
}
return bt;
}
BiTree DeleteL(BiTree bt, BiTree parent)
{ BiTree p;
if (parent= =NULL||parent->lchild= =NULL) return NULL;
p= parent->lchild;
parent->lchild=NULL;
freeAll((5));
return bt;
设有下列定义:struct sk{ int m; float x; }data,*q;若要使q指向data中的m域,正确的赋值语句是()。
A.q=&data.m;
B.q=data.m;
C.q=(struct sk*)&data.m;
D.q=(struct sk*)data.m;

















