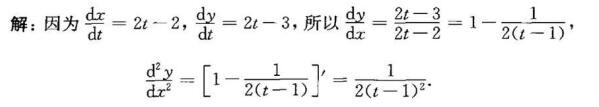题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在例8.7中, 我们计算了香烟需求方程的OLS和一系列WLS估计值。(i)求方程(8.35)中的OLS估计值。(iv
在例8.7中, 我们计算了香烟需求方程的OLS和一系列WLS估计值。(i)求方程(8.35)中的OLS估计值。(iv
在例8.7中, 我们计算了香烟需求方程的OLS和一系列WLS估计值。
(i)求方程(8.35)中的OLS估计值。

(iv)第(iii)部分的结论对于求式(8.36)时建议使用的同方差形式有何含义?
(v)在容许方差函数被误设的情况下,求WLS估计值的确当标准误。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“在例8.7中, 我们计算了香烟需求方程的OLS和一系列WLS…”相关的问题
更多“在例8.7中, 我们计算了香烟需求方程的OLS和一系列WLS…”相关的问题
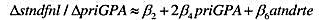
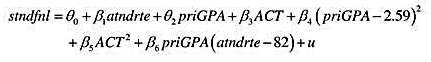
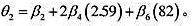 (注意,截距已发生变化,但并不重要。)用它求出第(i)部分得到的θ2的标准差。
(注意,截距已发生变化,但并不重要。)用它求出第(i)部分得到的θ2的标准差。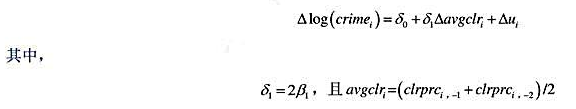
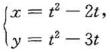 所确定的函数的一阶导数dy/dx与二阶导数
所确定的函数的一阶导数dy/dx与二阶导数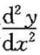 。
。