 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
如果模型中的解释变量存在完全的多重共线性,则参数的最小二乘估计量是()
A.无偏的
B.有偏的
C.不确定
D.确定的
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.无偏的
B.有偏的
C.不确定
D.确定的
如果结果不匹配,请 联系老师 获取答案
 更多“如果模型中的解释变量存在完全的多重共线性,则参数的最小二乘估…”相关的问题
更多“如果模型中的解释变量存在完全的多重共线性,则参数的最小二乘估…”相关的问题
为了检验抵押贷款市场中的歧视,可使用一个线性概率模型:
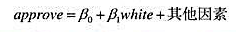
(i)如果对少数民族存在歧视,并控制了适当的因素,那么,的符号是什么?
(ii)将qpxe对white做回归,并以通常的形式报告结果。解释white的系数。它是统计显著的吗?它实际上大吗?
(iii)作为控制因素,增加变量hrat,obrat,loanprc,unem,male,married,dep,sch,cosign,chist,pubrec,mortlatl,mortlat2和vr。white的系数会有什么变化?仍有对非白人存在歧视的证据吗?
(iv)现在容许种族效应与度量了其他债务占收入比例的变量(obrat)存在着交互作用。交互项显著吗?
(v)利用第(iv)部分的模型,当债务负担达到样本均值obrat=32时,作为白人对贷款许可的概率有多大的影响?构造这种影响的一个95%的置信区间。
A.异方差
B.完全多重共线
C.遗漏变量偏差
D.虚拟变量陷阱
本题使用ATTEND.RAW中的数据。
(i)求出变量atndrte,pricGPA和ACT的最小值、最大值和平均值。
(ii)估计模型atndrte=β0+β1pricGPA+β2ACT+u,并以方程的形式写出结论。对截距做出解释。它是否有一个有用的含义。
(iii)讨论估计的斜率系数。有没有什么令人吃惊之处?
(iv)如果priGPA=3.65和ACT=20,预计atndrte是多少?你对这个结论做何解释?样本中有没有一些学生具有这些解释变量的值?
(v)如果学生A具有priGPA=3.1和ACT=21,而学生B具有priGPA=2.1和ACT=26,他们在出勤率上的预期差异是多少?
变量选择是用来选择最好的判别器子集,如果要考虑模型效率,我们应该做哪些变量选择的考虑()
1.多个变量其实有相同的用处
2.变量对于模型的解释有多大作用
3.特征携带的信息
4.交叉验证
A.1和4
B.1,2和3
C.1,3和4
D.以上所有
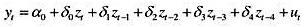
现在假定δj是j的二次函数: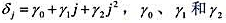 为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
(i)将每个δj的公式代入分布滞后模型,并把它写成用γh表示的模型h=0,1,2。
(ii)解释你用来估计γh的回归方程。
(iii)上面的多项式分布滞后模型是一般模型的一个约束形式。它受到了多少个约束?你如何来检验它们?(提示:用F检验。)
利用PNTSPRD.RAW中的数据。
(i)变量favwin是一个二值变量,在拉斯维加斯所押的球队胜出了预定的分数差时取值1。估计所押球队获胜概率的线性概率模型为
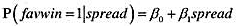
如果分数差包括了所有相关的信息,那我们预期β0=0.5。请解释。
(ii)用OLS估计第(i)部分的模型。相对于双侧备择假设检验H0:β0=0.5。同时使用通常的标准误和异方差一稳健的标准误。
(iii)spread在统计上显著吗?当spread=10时,被押球队获胜的估计概率是多少?
(iv)现在对P(favwin=Ilspread)估计一个概率单位模型。解释和检验截距项为0的虚拟假设。[提示:注意Φ(0)=0.5。]
(v)利用概率单位模型估计当spread=10时被押球队获胜的概率。并与第(iii)部分的LPM估计值相比较。
(vi)在概率单位模型中增加变量fuvhome、fav25和und25,并用似然比检验来检验这些变量的联合显著性。(x2分布中的自由度是多少?)解释这个结果,注意分数差是否包括了赛前可观测到的全部信息这个问题。
利用MRO2.RAW中的数据。
(i)利用在工作的428个妇女的数据,通过以exper、exper2、nwifeinc、age、kidsir6和kidsge6为解释变量的OLS来估计受教育的回报。报告educ的估计值及其标准误。
(ii)现在用赫克曼估计受教育的回报,其中所有外生变量都在第二阶段的回归中出现。换句话说,就是做log(wage)对educ、exper、ecper2、nwifeinc、age、kidslt6、kidsge6和入的回归。将估计的教育回报及其标准误与第(i)部分的结果相比较。
(iii)只用428个工作妇女的观测,将1对educ、exper、ecper2、nwifeinc、age、kidslt6、kidsge6回归。R2为多大?这如何有助于解释你在第(ii)部分得到的结果?(提示:考虑多重共线性。)
利用APPLE.RAW中的数据。这些电话调查数据是为了得到(假想的)“环保”苹果需求。调查者向每个家庭都(随机地)介绍了正常苹果和环保苹果的一组价格,并询问他们愿意购买每种苹果的磅数。
(i)对于样本中的660个家庭,有多少家庭报告称在预定价格上不愿意购买环保苹果?
(ii)变量ecolbs看上去在严格正值上具有连续分布吗?你的回答对ecolbs托宾模型的适当性有何含义?
(iii)以ecoprc、regprc、famic和hhsize作为解释变量,估计一个托宾模型。哪些变量在1%的水平上显著。
(iv)faminc和hhsize联合显著吗?
(v)第(iii)部分中价格变量系数的符号与你的预期一致吗?请解释。
(vi)令β1和β2为ecoprc和regprc的系数,相对一个双侧备择假设,检验假设H0:-β1=β2。报告检验的p值。(如果你的回归软件不能很容易地计算这种检验,你可能还要参考教材4.4节
(vii)对样本中的所有观测求E(ecolbslx)的估计值[见方程(17.25)],称之为ecolbsi。最大和最小拟合值是多少?
(viii)计算ecolbs,和ecolbsi之相关系数的平方。
(ix)现在,利用第(iii)部分中同样的解释变量,估计ecolbs的一个线性模型。为什么OLS估计值比托宾估计值小那么多?从拟合优度来看,托宾模型比线性模型更好吗?
(x)评价如下命题:“由于托宾模型的R,如此之小,所以估计的价格效应可能是不一致的。”

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差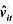 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用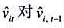 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为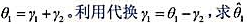 的标准误。
的标准误。
(i)使用RETURN.RAW中的数据,估计了如下方程:
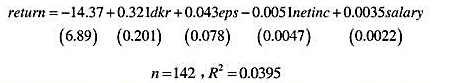
检验这些解释变量在5%的显著性水平上是否联合显著。存在个别显著的解释变量吗?
(ii)现在使用netinc和salary的对数形式重新估计这个模型
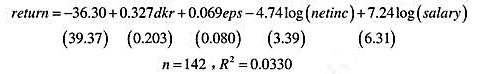
第(i)部分的结论有没有什么变化?
(iii)在第(ii)部分中,我们为什么不用dks和eps的对数?
(iv)总的看来,股票回报可预测性的证据是强还是弱?

















