 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
设主串t和模式串p分别是由d(d≥2)元字符集中随机字符组成的长度为n和m的字符串.试证明简单子串
设主串t和模式串p分别是由d(d≥2)元字符集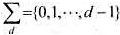 中随机字符组成的长度为n和m的字符串.试证明简单子串搜索算法所做比较次数的期望值为
中随机字符组成的长度为n和m的字符串.试证明简单子串搜索算法所做比较次数的期望值为
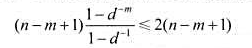
由此可见,对于随机选取的字符串,简单子串搜索算法还是十分有效的.
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
设主串t和模式串p分别是由d(d≥2)元字符集中随机字符组成的长度为n和m的字符串.试证明简单子串搜索算法所做比较次数的期望值为
由此可见,对于随机选取的字符串,简单子串搜索算法还是十分有效的.
如果结果不匹配,请 联系老师 获取答案
 更多“设主串t和模式串p分别是由d(d≥2)元字符集中随机字符组成…”相关的问题
更多“设主串t和模式串p分别是由d(d≥2)元字符集中随机字符组成…”相关的问题
试题四(共15分)
阅读下列说明和C代码,回答问题1至问题3,将解答写在答题纸的对应栏内。
【说明】
模式匹配是指给定主串t和子串s,在主串t中寻找子串s的过程,其中s称为模式。
如果匹配成功,返回s在t中的位置,否则返回-1 。
KMP算法用next数组对匹配过程进行了优化。KMP算法的伪代码描述如下:
1.在串t和串s中,分别设比较的起始下标i=J=O
2.如果串t和串s都还有字符,则循环执行下列操作:
(1)如果j=-l或者t[i]-s[j],则将i和j分别加1,继续比较t和s的下一个字符;
(2)否则,将j向右滑动到next[j]的位置,即j =next[J]
3.如果s中所有字符均已比较完毕,则返回匹配的起始位置(从1开始);否则返回一1.
其中,next数组根据子串s求解。求解next数组的代码已由get_next函数给出。
【C代码】
(1)常量和变量说明
t,s:长度为悯铂Is的字符串
next:next数组,长度为Is
(2)C程序
include <stdio.h>
nclude <stdliB.h>
include <string.h>
/*求next【】的值*/
void get_next(int *next, char *s, int Is) {
int i=0,j=-1;
next[0]=-1;/*初始化next[0]*/
while(i< ils){/*还有字符*/
if(j=-1l ls[i]=s[j]){/*匹配*/
j++;
i++;
if(s[i]一s[jl)
next [i]- next[j];
else
Next[i]=j;
}
else
J= next[j];
}
}
int kmp(int *next, char *t ,char *s, int.lt, int Is )
{
inti= 0,j =0 ;
while (i<lt && (1 ) {
if(j=-1 II 2_) {
i++ ;
j ++ ;
} else
(3) :
}
if (j>= ls)
Retum (4)
else .
retum-1;
【问题1】(8分)
根据题干说明,填充C代码中的空(1)~(4).
【问题2】(2分)
根据题干说明和C代码,分析出kmp算法的时间复杂度为 (5)(主串和子的长度分别为It和Is,用O符号表示)。
【问题3】(5分)
根据C代码,字符串“BBABBCAC”的next数组元素值为 (6) (直接写素值,之间用逗号隔开)。若主串为“AABBCBBABBCACCD”,子串为“BBABBCAC则函数Kmp的返回值是 (7)
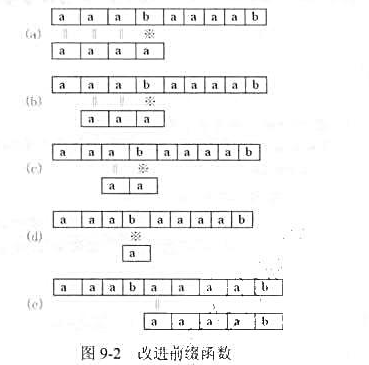
在图9-2(a)中匹配失败后,按前缀函数指示继续作了图(b)~(d)的比较后,最后在图(e)找到一个匹配.事实上,图(b)~(d)的比较都是多余的.因为模式串在位置0、1、2处的字符和位置3处的字符都相等,因此不需要再和主串中位置3处的字符比较,而可以将模式一次向右滑动4个字符,直接进入图(e)的比较.这就是说,在KMP算法中遇到p[j+1]≠t[i],且p[j+1]=p[next[j]+1]时,可一次向右滑动j-next[next[j]]个字符,而不是j-next[j]个字符.根据此观察,设计一个改进的前缀函数,使得遇到上述特殊情况时效率更高.
在目标串T[0,n-1]=”xwxxyxy”中,对模式串p[0,m-1]=”xy”进行子串定位操作的结果_______
A.0
B.2
C.3
D.5
●试题五
阅读以下程序说明和C程序,将应填入(n)处的子句,写在答卷纸的对应栏内。
【程序说明】
函数int commstr(char *str1,char *str2,int *sublen)从两已知字符串str1和str2中,找出它们的所有最长的公共子串。如果最长公共子串不止1个,函数将把它们全部找出并输出。约定空串不作为公共子串。
函数将最长公共子串的长度送入由参数sublen所指的变量中,并返回字符串str1和str2的最长公共子串的个数。如果字符串str1和str2没有公共子串,约定最长公共子串的个数和最长公共子串的长度均为0。
【程序】
int strlen(char *s)
{char *t=s;
while(*++);
return t-s-1;
}
intcommstr(char)*str1,char *str2,int *sublen
{char*s1,*s2;
int count=0,len1,len2,k,j,i,p;
len1=strlen(str1);
len2=strlen(str2);
if(len1>len2)
{s1=str1;s2=str2;}
else{len2=len1;s1=str2;s2=str1;}
for(j=len2;j>0;j--)/*从可能最长子串开始寻找*
{for(k=0; (1) <=len2;k++)/*k为子串s2的开始位置*/
{for(i=0;s1[ (2) ]!='\0';i++;)/* i为子串s1的开始位置*/
{/* s1的子串与s2的子串比较*/
for(p=0;p<j)&& (3) ;p++);
if ((4) )/*如果两子串相同*/
{for(p=0);p<j;p++}/*输出子串*/
printf("%c",s2[k+p]);
printf("\n");
count++;/* 计数增1*/
}
}
}
if (count>0)break;
*sublen=(count>0)? (5) :0;
return count;
}
没有两个串p和q,求q在p首次出现位置的运算称作
A.连接
B.模式匹配
C.求于串
D.求串长
设关系R和关系S的元素分别是4和5,关系T是R与S的笛卡尔积,即:T= R×S,则关系T的元数是()。
A.9
B.16
C.20
D.25
则
A)T 的元数是(r+s),且有(n+m)个元组
B)T 的元数是(r+s),且有(n×m)个元组
C)T 的元数是(r×s),且有(n+m )个元组
D)T 的元数是(r×s),且有(n×m)个元组

(58)A. 0123123
B. 0123210
C. 0123432
D. 0123456

(57)
A. 01111111
B.01122341
C.01234567
D.01122334

















