 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
参数估计是()。
A.用一个参数去估计另一个参数
B.用一个统计量去估计另一个统计量
C.用参数去估计统计量
D.用统计量去估计参数
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.用一个参数去估计另一个参数
B.用一个统计量去估计另一个统计量
C.用参数去估计统计量
D.用统计量去估计参数
如果结果不匹配,请 联系老师 获取答案
 更多“参数估计是()。”相关的问题
更多“参数估计是()。”相关的问题
语言模型的参数估计经常使用MLE(最大似然估计)。面临的一个问题是没有出现的项概率为0,这样会导致语言模型的效果不好。为了解决这个问题,需要使用()
A.平滑
B.去噪
C.随机插值
D.增加白噪音
A.正则条件在任何情况下都是成立的
B.任意无偏估计量的方差都要大于等于CRLB
C.达到CRLB的无偏估计称为有效估计量
D.Fisher信息越大,CRLB越小
在HMM中,如果已知观察序列和产生观察序列的状态序列,那么可用以下哪种方法直接进行参数估计()
A.EM算法
B.维特比算法
C.前向后向算法
D.极大似然估计
利用PHILLIPS.RAW中的数据,但只到1996年。
(i)在教材例11.5中,我们假定自然失业率是常数。在另一种形式的附加预期的菲利普斯曲线中,自然失业率受历史失业水平的影响。最简单的情况是,t时期的自然失业率与unemt-1,相等。如果我们假定适应性预期,便得到一个通货膨胀和失业率都是一阶差分形式的菲利普斯曲线: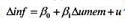 估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
估计这个模型,以常见格式报告结果,并讨论β1的符号、大小和统计显著性。
(ii)教材(11.19)和第(i)部分中的模型,哪一个对数据拟合得更好?说明理由。
下列情况中,不会调用复制构造函数的是
A.用一个对象去初始化同一类的另一个新对象时
B.将类的一个对象赋予该类的另一个对象时
C.函数的形参是类的对象,调用函数进行形参和实参结合时
D.函数的返回值是类的对象,函数执行返回调用时
我们估计了一个线性概率模型以说明一个年轻人在1986年是否被拘捕:

(i)用OLS估计此模型,并验证其全部估计值都严格地介于0和1之间。最大和最小的估计值各是多少?
(ii)用加权最小二乘法估计这个方程。
(iii)用WLS估计值决定avgsen和tottime在5%的显著性水平上是否联合显著。
下列情况中,不会调用拷贝构造函数的是()。
A.用一个对象去初始化同一类的另一个新对象时
B.将类的一个对象赋值给该类的另一个对象时
C.函数的形参是类的对象,调用函数进行形参和实参结合时
D.函数的返回值是类的对象,函数执行返回调用时
下列有关模板的叙述中,正确的是
A.函数模板不能含有常规形参
B.函数模板的一个实例就是一个函数定义
C.类模板的成员函数不能是模板函数
D.用类模板定义对象时,绝对不能省略模板实参
A.拷贝构造函数是一种构造函数
B.拷贝构造函数与一般的构造函数一样,可以设置多个形参
C.每一个类中都必须有一个拷贝构造函数
D.拷贝构造函数的功能是用一个已知对象去初始化一个正在创建的对象。
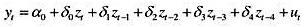
现在假定δj是j的二次函数: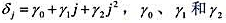 为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
为参数。这是多项式分布滞后(polynomialdistributedlag,PDL)模型的一个例子。
(i)将每个δj的公式代入分布滞后模型,并把它写成用γh表示的模型h=0,1,2。
(ii)解释你用来估计γh的回归方程。
(iii)上面的多项式分布滞后模型是一般模型的一个约束形式。它受到了多少个约束?你如何来检验它们?(提示:用F检验。)
利用BARIUM.RAW中的数据。
(i)用前119次观测(即不包含1988年的最后12个月观测),估计线性趋势模型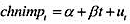 。这个回归的标准误是什么?
。这个回归的标准误是什么?
(ii)同样用除了最后12个月以外的所有数据,估计chnimp的一个AR(1)模型。把这个回归的标准误与第(i)部分中的标准误相比较。哪一个模型提供了更好的样本内拟合?
(iii)用第(i)和第(ii)部分中的模型计算1988年12个月的提前一期预测误差。(每个方法都应该得到12个预测误差。)计算并比较这两种方法的RMSE和MAE。就样本外提前一期预测而言,哪种方法效果更好?
(iv)在第(i)部分的回归中添加月度虚拟变量。它们是联合显著的吗?(当我们检验联合显著性时,不必担心误差中轻度的序列相关。)

















