 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[判断题]
根据Hall各异条件,一个N个变量,N个方程构成的方程组,若对每个方程可以指定一个变量作为输出变量,且该变量不再作为其它方程的输出变量,则该方程组必定有解()
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
 更多“根据Hall各异条件,一个N个变量,N个方程构成的方程组,若…”相关的问题
更多“根据Hall各异条件,一个N个变量,N个方程构成的方程组,若…”相关的问题
阅读下列函数说明和C代码,回答下面问题。
[说明]
冒泡排序算法的基本思想是:对于无序序列(假设扫描方向为从前向后,进行升序排列),两两比较相邻数据,若反序则交换,直到没有反序为止。一般情况下,整个冒泡排序需要进行众(1≤k≤n)趟冒泡操作,冒泡排序的结束条件是在某一趟排序过程中没有进行数据交换。若数据初态为正序时,只需1趟扫描,而数据初态为反序时,需进行n-1趟扫描。在冒泡排序中,一趟扫描有可能无数据交换,也有可能有一次或多次数据交换,在传统的冒泡排序算法及近年的一些改进的算法中[2,3],只记录一趟扫描有无数据交换的信息,对数据交换发生的位置信息则不予处理。为了充分利用这一信息,可以在一趟全局扫描中,对每一反序数据对进行局部冒泡排序处理,称之为局部冒泡排序。
局部冒泡排序的基本思想是:对于N个待排序数据组成的序列,在一趟从前向后扫描待排数据序列时,两两比较相邻数据,若反序则对后一个数据作一趟前向的局部冒泡排序,即用冒泡的排序方法把反序对的后一个数据向前排到适合的位置。扫描第—对数据对,若反序,对第2个数据向前冒泡,使前两个数据成为,有序序列;扫描第二对数据对,若反序,对第3个数据向前冒泡,使得前3个数据变成有序序列;……;扫描第i对数据对时,其前i个数据已成有序序列,若第i对数据对反序,则对第i+1个数据向前冒泡,使前i+1个数据成有序序列;……;依次类推,直至处理完第n-1对数据对。当扫描完第n-1对数据对后,N个待排序数据已成了有序序列,此时排序算法结束。该算法只对待排序列作局部的冒泡处理,局部冒泡算法的
名称由此得来。
以下为C语言设计的实现局部冒泡排序策略的算法,根据说明及算法代码回答问题1和问题2。
[变量说明]
define N=100 //排序的数据量
typedef struct{ //排序结点
int key;
info datatype;
......
}node;
node SortData[N]; //待排序的数据组
node类型为待排序的记录(或称结点)。数组SortData[]为待排序记录的全体称为一个文件。key是作为排序依据的字段,称为排序码。datatype是与具体问题有关的数据类型。下面是用C语言实现的排序函数,参数R[]为待排序数组,n是待排序数组的维数,Finish为完成标志。
[算法代码]
void Part-BubbleSort (node R[], int n)
{
int=0 ; //定义向前局部冒泡排序的循环变量
//暂时结点,存放交换数据
node tempnode;
for (int i=0;i<n-1;i++) ;
if (R[i].key>R[i+1].key)
{
(1)
while ((2) )
{
tempnode=R[j] ;
(3)
R[j-1]=tempnode ;
Finish=false ;
(4)
} // end while
} // end if
} // end for
} // end function
阅读下列函数说明和C代码,将应填入(n)处的字句写在的对应栏内。
阅读下列算法说明和流程图,根据要求回答问题1~问题3。
[说明]
某机器上需要处理n个作业job1,job2,…,jobn,其中:
(1)每个作业jobi(1≤i≤n)的编号为i,jobi有一个收益值P[i]和最后期限值d[i];
(2)机器在一个时刻只能处理一个作业,而且每个作业需要一个单位时间进行处理,一旦作业开始就不可中断,每个作业的最后期限值为单位时间的正整数倍;
(3)job1~jobn的收益值呈非递增顺序排列,即p[1]≥p[2]≥…≥p[n];
(4)如果作业jobi在其期限之内完成,则获得收益p[i];如果在其期限之后完成,则没有收益。
为获得较高的收益,采用贪心策略求解在期限之内完成的作业序列。图3-25是基于贪心策略求解该问题的流程图。
(1)整型数组J[]有n个存储单元,变量k表示在期限之内完成的作业数,J[1..k]存储所有能够在期限内完成的作业编号,数组J[1..k)里的作业按其最后期限非递减排序,即d[J[1]]≤…≤d[J[k]]。
(2)为了便于在数组J中加入作业,增加一个虚拟作业job0,并令d[0]=0,J[0]=0。
(3)算法大致思想是:先将作业job1的编号1放入J[1],然后,依次对每个作业jobi(2≤i≤n)进行判定,看其能否插入到数组J中。若能,则将其编号插入到数组J的适当位置,并保证J中作业按其最后期限非递减排列;否则不插入。
jobi能插入数组J的充要条件是:jobi和数组J中已有作业均能在其期限之内完成。
(4)流程图中的主要变量说明如下。
i:循环控制变量,表示作业的编号;
k:表示在期限内完成的作业数;
r:若jobi能插入数组J,则其在数组J中的位置为r+1;
q:循环控制变量,用于移动数组J中的元素。
.jpg)
请将图3-25中的(1)~(3)空缺处的内容填写完整。
A.n个变量的积项,它包含全部n个变量
B.n个变量的和项,它包含n个原变量
C.每个变量都以原、反变量的形式出现,且仅出现一次
D.n个变量的和项,它不包含全部变量
试题四(共15分)
阅读下列说明和C代码,回答问题1至问题3,将解答写在答题纸的对应栏内。
【说明】
用两台处理机A和B处理n个作业。设A和B处理第i个作业的时间分别为ai和bi。由于各个作业的特点和机器性能的关系,对某些作业,在A上处理时间长,而对某些作业在B上处理时间长。一台处理机在某个时刻只能处理一个作业,而且作业处理是不可中断的,每个作业只能被处理一次。现要找出一个最优调度方案,使得n个作业被这两台处理机处理完毕的时间(所有作业被处理的时间之和)最少。
算法步骤:
(1)确定候选解上界为R短的单台处理机处理所有作业的完成时间m,

(2)用p(x,y,k)=1表示前k个作业可以在A用时不超过x且在B用时不超过y时间 内处理完成,则p(x,y,k)=p(x-ak,y,k-1)||p(x,y-bk,k-1)(表示逻辑或操作)。
(3)得到最短处理时问为min(max(x,y))。
【C代码】
下面是该算法的C语言实现。
(1)常量和变量说明
n: 作业数
m: 候选解上界
a: 数组,长度为n,记录n个作业在A上的处理时间,下标从0开始
b: 数组,长度为n,记录n个作业在B上的处理时间,下标从0开始
k: 循环变量
p: 三维数组,长度为(m+1)*(m+1)*(n+1)
temp: 临时变量
max: 最短处理时间
(2)C代码
include<stdio.h>
int n, m;
int a[60], b[60], p[100][100][60];
void read(){ /*输入n、a、b,求出m,代码略*/}
void schedule(){ /*求解过程*/
int x,y,k;
for(x=0;x<=m;x++){
for(y=0;y<m;y++){
(1)
for(k=1;k<n;k++)
p[x][y][k]=0;
}
}
for(k=1;k<n;k++){
for(x=0;x<=m;x++){
for(y=0;y<=m;y++){
if(x - a[k-1]>=0) (2) ;
if((3) )p[x][y][k]=(p[x][y][k] ||p[x][y-b[k-1]][k-1]);
}
}
}
}
void write(){ /*确定最优解并输出*/
int x,y,temp,max=m;
for(x=0;x<=m;x++){
for(y=0;y<=m;y++){
if((4) ){
temp=(5) ;
if(temp< max)max = temp;
}
}
}
printf("\n%d\n",max),
}
void main(){read();schedule();write();}
【问题1】 (9分)
根据以上说明和C代码,填充C代码中的空(1)~(5)。
【问题2】(2分)
根据以上C代码,算法的时间复杂度为(6)(用O符号表示)。
【问题3】(4分)
考虑6个作业的实例,各个作业在两台处理机上的处理时间如表4-1所示。该实例的最优解为(7),最优解的值(即最短处理时间)为(8)。最优解用(x1,x2,x3,x4,x5,x6)表示,其中若第i个作业在A上赴理,则xi=l,否则xi=2。如(1,1,1,1,2,2)表示作业1,2,3和4在A上处理,作业5和6在B上处理。

试题四(共15分)
阅读下列说明和C代码,回答问题1至问题3,将解答写在答题纸的对应栏内。
【说明】
设有n个货物要装入若干个容量为C的集装箱以便运输,这n个货物的体积分别为{S1,S2,...,Sn},且有si≤C(1≤i≤ n)。为节省运输成本,用尽可能少的集装箱来装运这n个货物。
下面分别采用最先适宜策略和最优适宜策略来求解该问题。
最先适宜策略(firstfit)首先将所有的集装箱初始化为空,对于所有货物,按照所给的次序,每次将一个货物装入第一个能容纳它的集装箱中。
最优适宜策略(bestfit)与最先适宜策略类似,不同的是,总是把货物装到能容纳它且目前剩余容量最小的集装箱,使得该箱子装入货物后闲置空间最小。
【C代码】
下面是这两个算法的C语言核心代码。
(1)变量说明
n:货物数
C:集装箱容量
s:数组,长度为n,其中每个元素表示货物的体积,下标从0开始
b:数组,长度为n,b[i]表示第i+1个集装箱当前已经装入货物的体积,下标从0开始
i,j:循环变量
k:所需的集装箱数
min:当前所用的各集装箱装入了第i个货物后的最小剩余容量
m:当前所需要的集装箱数
temp:临时变量
(2)函数firstfit
int firstfit(){
inti,j;
k=0:
for(i=0;i<n;i++){
b[i]=0;
}
for(i=0;i<n;i++){
(1);
while(C-b[j]<s[i]){
j++;
}
(2);
k=k>(j+1)?k:(j+1);
}
returnk;
}
(3)函数bestfit
int bestfit() {
int i,j,min,m,temp;
k=0;
for(i=0;i<n;i++){
b[i]=0;
}
For (i=0;i<n;i++){
min=C;
m=k+l;
for(j=O;j< k+l;j++){
temp=C- b[j] - s[i];
if(temp>0&&temp< min){
(3) ;
m=j,
}
}
(4);
k=k>(m+1)?k:(m+1);
}
return k;
}
【问题1】(8分)
根据【说明】和【C代码】,填充C代码中的空(1)~(4)。
【问题2】(4分)
根据【说明】和【C代码】,该问题在最先适宜和最优适宜策略下分别采用了(5) 和(6)算法设计策略,时间复杂度分别为 (7) 和 (8)(用O符号表示)。
【问题3】(3分)
考虑实例n= 10,C= 10,各个货物的体积为{4,2,7,3,5,4,2,3,6,2}。该实例在最先适宜和最优适宜策略下所需的集装箱数分别为(9)和(10)。考虑一般的情况,这两种求解策略能否确保得到最优解?(11) (能或否)
在说明语句int *f();中,标识符f代表的是______。
A.一个用于指向整型数据的指针变量
B.—个用于指向—维数组的行指针
C.—个用于指向函数的指针变量
D.一个返回值为指针型的函数名
设a1,a2,...,an是n个不同的数,而F(x)=(x-a1)(x-a2)...(x-an),b1,b2,...,bn是任意n个数,显然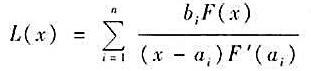 适合条件L(ai)=bi,i=1,2,...,n。这称为拉格朗日(Lagrange)插值公式。
适合条件L(ai)=bi,i=1,2,...,n。这称为拉格朗日(Lagrange)插值公式。
利用上面的公式求:
1)一个次数<4的多项式f(x),它适合条件:f(2)=3,f(3)=-1,f(4)=0,f(5)=2。
2)一个二次多项式f(x),它在x=0,2/π,π处与函数sinx有相同的值。
3)一个次数尽可能低的多项式f(x),使f(0)=1,f(1)=2,f(2)=5,f(3)=10。
A.M个指向整型变量的指针
B.指向M个整型变量的函数指针
C.一个指向具有M个整型元素的一维数组的指针
D.具有M个指针元素的一维指针数组,每个元素都只能指向整型量

















