

 如果结果不匹配,请
如果结果不匹配,请 
 更多“如果SVM模型欠拟合,可以增大惩罚参数C的值。()”相关的问题
更多“如果SVM模型欠拟合,可以增大惩罚参数C的值。()”相关的问题
第2题
1952年--1997年我国人均国内生产总值(单位:元)数据如表8.3所列。(1)用ARIMA(2,1,1)模型拟合,求
1952年--1997年我国人均国内生产总值(单位:元)数据如表8.3所列。(1)用ARIMA(2,1,1)模型拟合,求
点击查看答案
1952年--1997年我国人均国内生产总值(单位:元)数据如表8.3所列。
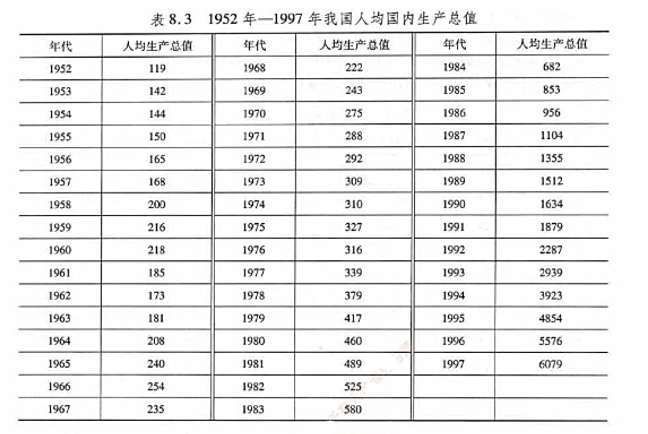 (1)用ARIMA(2,1,1)模型拟合,求模型参数的估计值;
(1)用ARIMA(2,1,1)模型拟合,求模型参数的估计值;
(2)求数据的10步预报值。
第3题
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0⌘
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0⌘
点击查看答案
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0+α1Xi+νi,试评述这一设定误差的后果。
(2)在(1)中,假设真实的模型是带截距项的模型,而你却对过原点的模型进行了普通最小二乘回归。请评述这一模型误设的后果。
第4题
下面三张图展示了对同一训练样本,使用不同的模型拟合的效果(蓝色曲线)。那么,我们可以得出哪些结论()
A.第1个模型的训练误差大于第2个、第3个模型
B.最好的模型是第3个,因为它的训练误差最小
C.第2个模型最为“健壮”,因为它对未知样本的拟合效果最好
D.第3个模型发生了过拟合
第7题
假如我们使用非线性可分的SVM目标函数作为最优化对象,我们怎么保证模型线性可分()A.设C=1B.设C=0
假如我们使用非线性可分的SVM目标函数作为最优化对象,我们怎么保证模型线性可分()
A.设C=1
B.设C=0
C.设C=无穷大
D.以上都不对
第8题
对于模型Yt=β1t+β2Xt+ut,β1t=α0+α1Zt,如果Zt为虚拟变量,则上述模型就是一个()。
A.常数参数模型
B.截距与斜率同时变动模型
C.截距变动模型
D.分段线性回归模型
第9题
考虑教材例10.6中那种形式的费尔模型。现在,我们不去预测民主党在两党选举中的得票比例,而去估
计一个表示民主党是否获胜的线性概率模型。
点击查看答案
(i)用虚拟变量demwins来代替教材(10.23)中的demvote,并用通常的格式报告结果。哪些因素影响获胜概率?请用截至1992年的数据。
(ii)有多少个拟合值小于0?有多少个拟合值大于1?
(iii)采用下面的预测规则:如果demwins>0.5,你就可以预测民主党会获胜;否则,共和党将获胜。那么,在这20次选举中,这个模型有多少次正确地预测了实际结果?
(iv)代入1996年的解释变量值。预测克林顿赢得这次选举的可能性有多大。事实上,克林顿获胜了,你的预测结果是否与事实相符?
(v)对误差中的AR(1)序列相关,做异方差-稳健:检验。你有何发现?
(vi)求出第(i)部分中估计值的异方差-稳健标准误。!统计量有什么明显的变化吗?
















